CXL 2.0 / PCIe Gen 5 - The Future of Composable Infrastructure

If you have been following H3 Platform, you may have seen our Falcon 5208 NVMe MR-IOV solution. The core idea of it is to increase storage utilization by leveraging SR-IOV of NVMe storage device and share the resources to multiple host machines through PCIe Gen 4 fabrics.
The architecture of this NVMe solution is illustrated as following diagram.
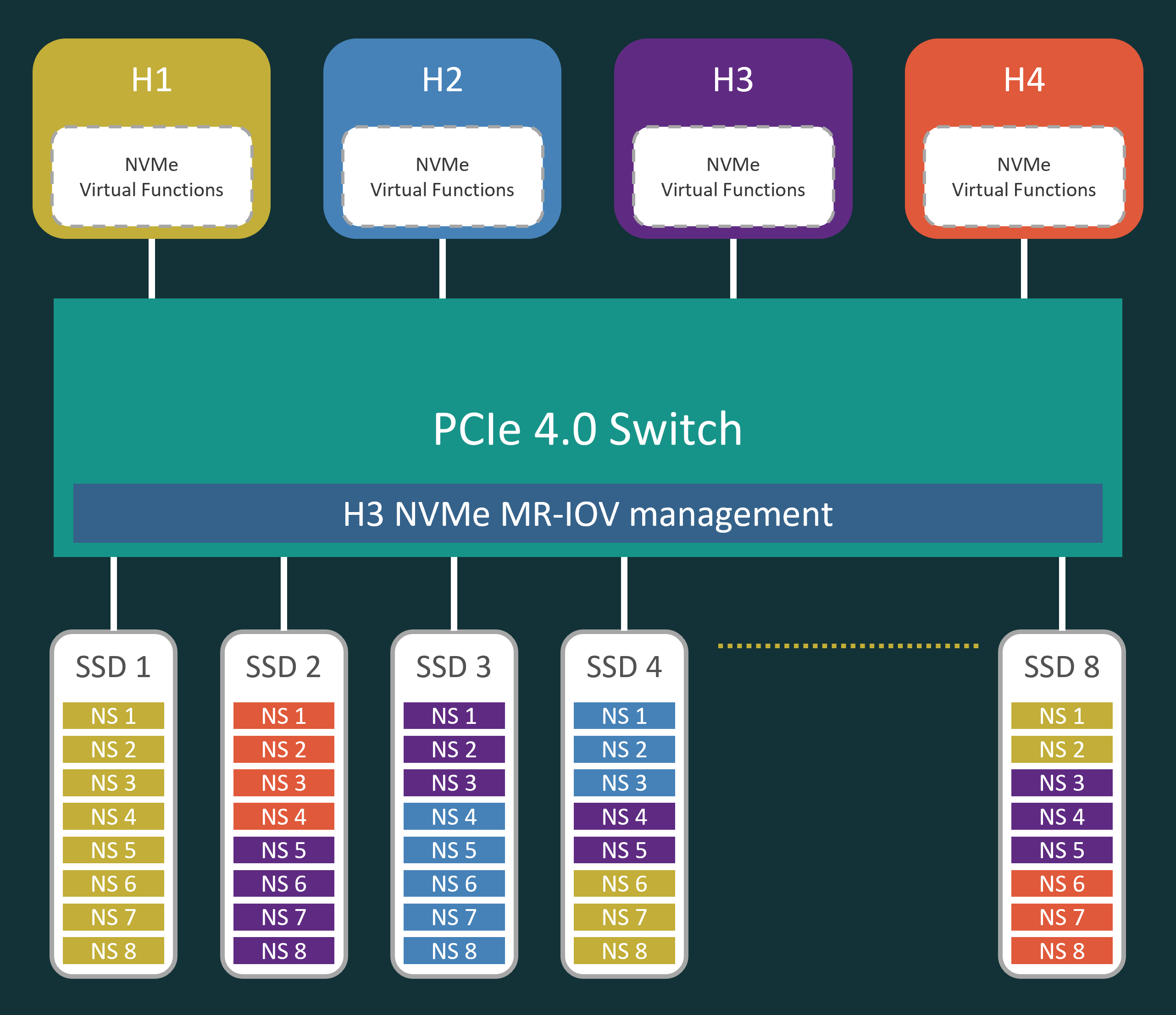
The SSDs are disaggregated from the CPU, SR-IOV of the NVMe SSDs is enabled in the Falcon NVMe chassis. This way, the storage resource is allocated into namespaces and bind to different CPU hosts through virtual functions.
Moving To CXL
Compute Express Link (CXL) was first developed by Intel, industry leaders such as AMD, Nvidia, Google...etc. soon formed a CXL Consortium to support the development. CXL is an industry-supported cache-coherent interconnect for processors, memory expansion and accelerators. It is designed to be an industry open standard interface for high-speed communications as accelerators are increasingly used to complement CPUs in support of emerging applications such as artificial intelligence and Machine Learning.
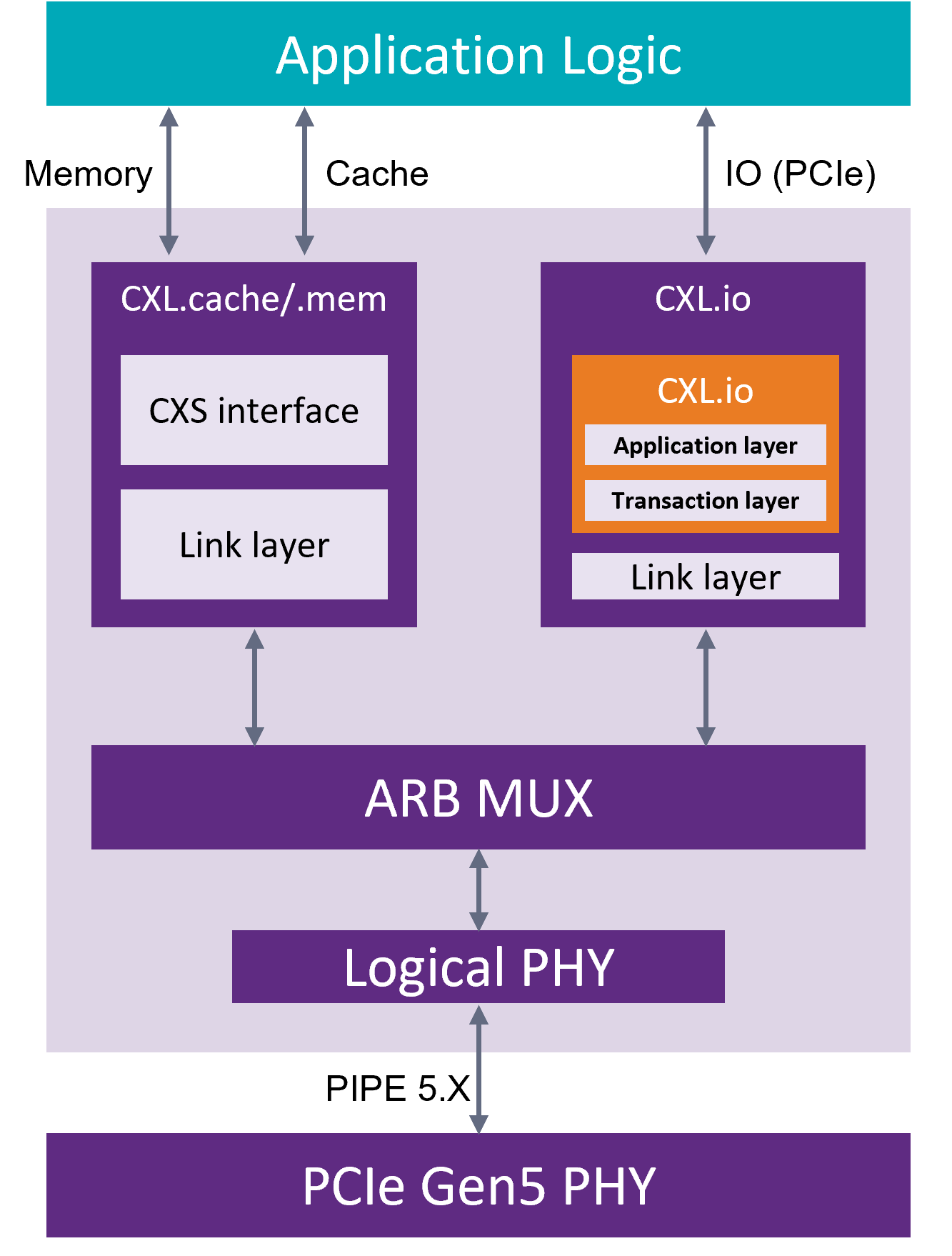
CXL specification is based on PCIe Gen 5, leverages its physical layer, allowing CPU to access shared memory on accelerator devices with a cache coherent protocol. The CXL standard defines three separate protocols: CXL.io, CXL.cache, and CXL.mem.
CXL.io: This protocol is functionally equivalent to the PCIe5.0 protocol and utilizes the broad industry adoption and familiarity of PCIe. As the foundational communication protocol, CXL.io is versatile and addresses a wide range of use cases.
CXL.cache: This protocol is designed for more specific applications, enables accelerators to efficiently access and cache host memory for optimized performance.
CXL.memory: This protocol enables a host, such as a processor, to access device-attached memory using load/store commands./p>
CXL also defines three device types, each require different combination of the three protocols.
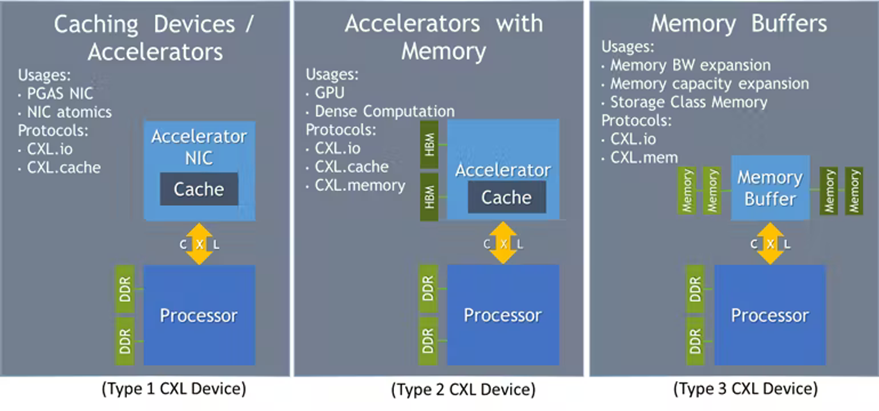
Type 1 device includes specialized accelerators (e.g., smart NIC) with no local memory. This type of devices relies on coherent access to host CPU memory. Type 2 device are general-purpose accelerators such as GPU, ASIC or FPGA with high-performance local memory. This type of devices can coherently access CPU memory and provide coherent or non-coherent access to device local memory from the host CPU.
Our focus today would be the type 3 device, the memory expansion or storage-class memory. This type of devices provides host CPU with low-latency access to local DRAM or non-volatile storage. The type 3 devices use CXL.io and CXL.mem protocols.
CXL Impact On Storage
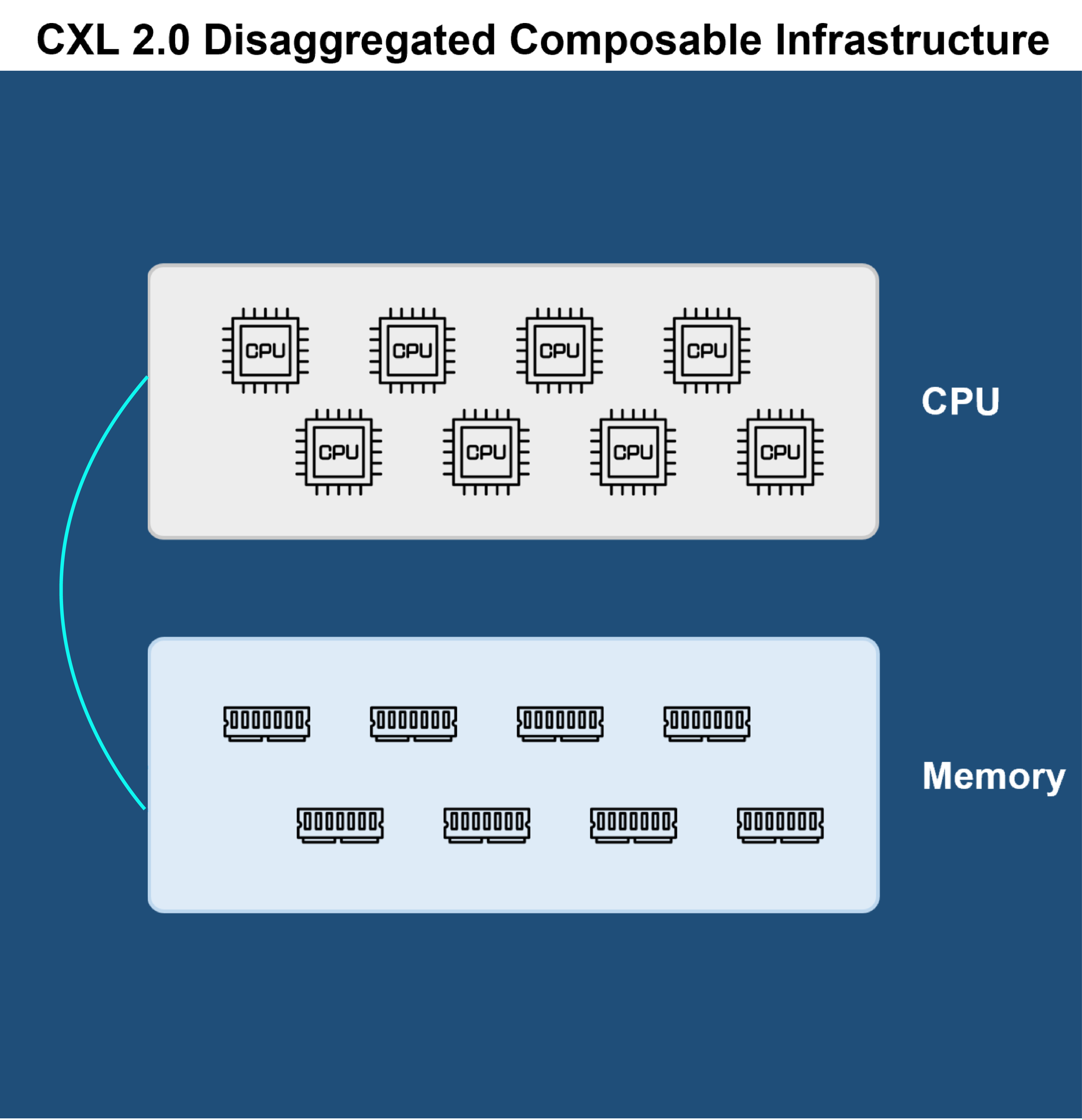
CXL will enable storage systems to take advantage of much larger memory pools for caching. The largest DRAM cache in commercial storage system is about 3TB, the Intel Optane Persistent Memory can extend that to 4.5 TB in some software-defined storage. CXL enables memory pool expansion by allowing storage software to cache data across multiple storage media, resulting in a higher read cache hit rate.
CXL 2.0 is the real game changer. Compared to CXL 1.0 and 1.1, CXL 2.0 introduces switching and pooling capability to the CXL protocol, this new specs are significant to disaggregation and composability of memory. With CXL switching, CXL devices can be bind and unbind to different host machines easily. The concept of our CXL storage system is quite similar to our Falcon NVMe MR-IOV solution which is introduced in the very beginning of this blog, but with larger bandwidth, lower latency, and with cache coherency.
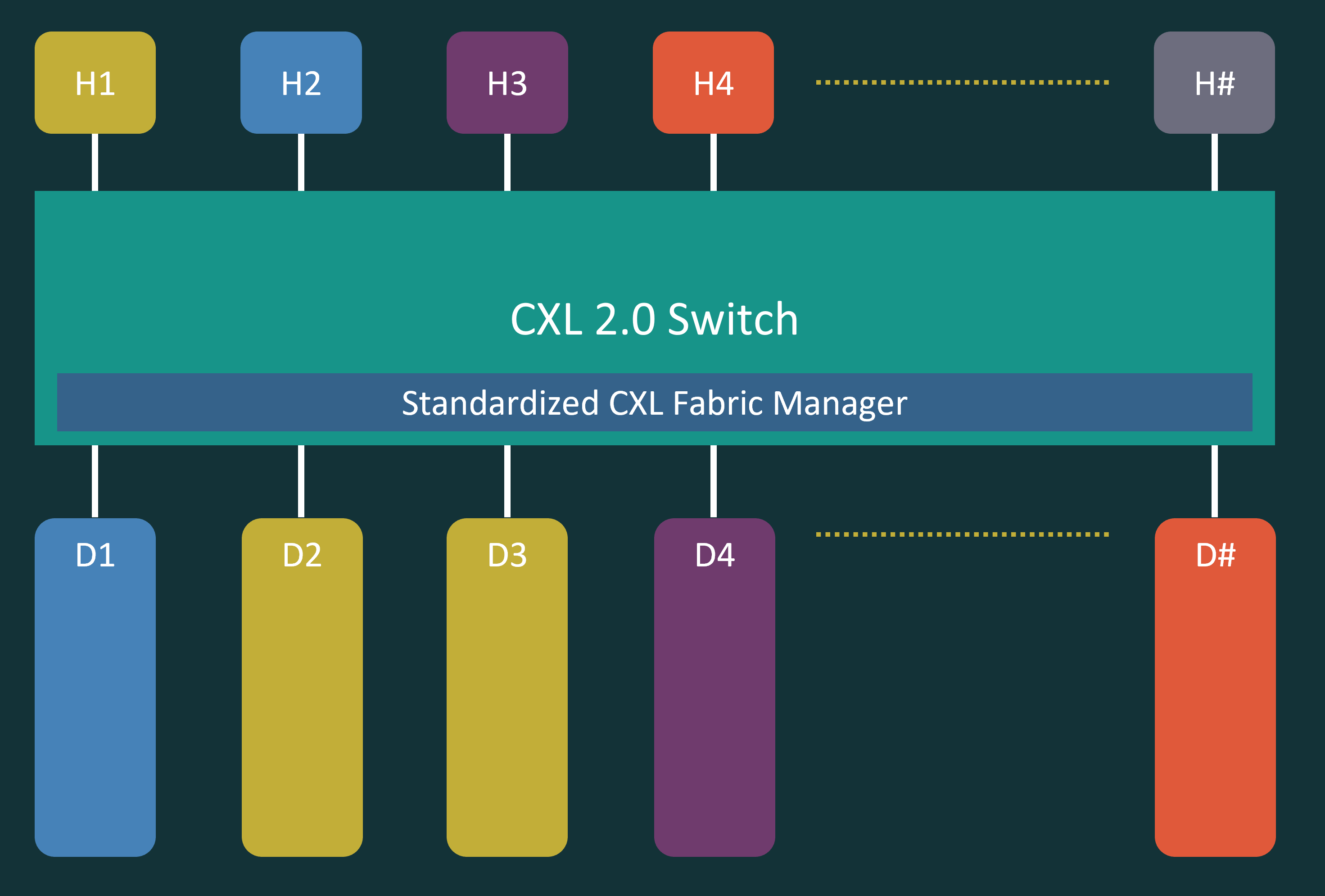
CXL2.0 Composable Memory Solution
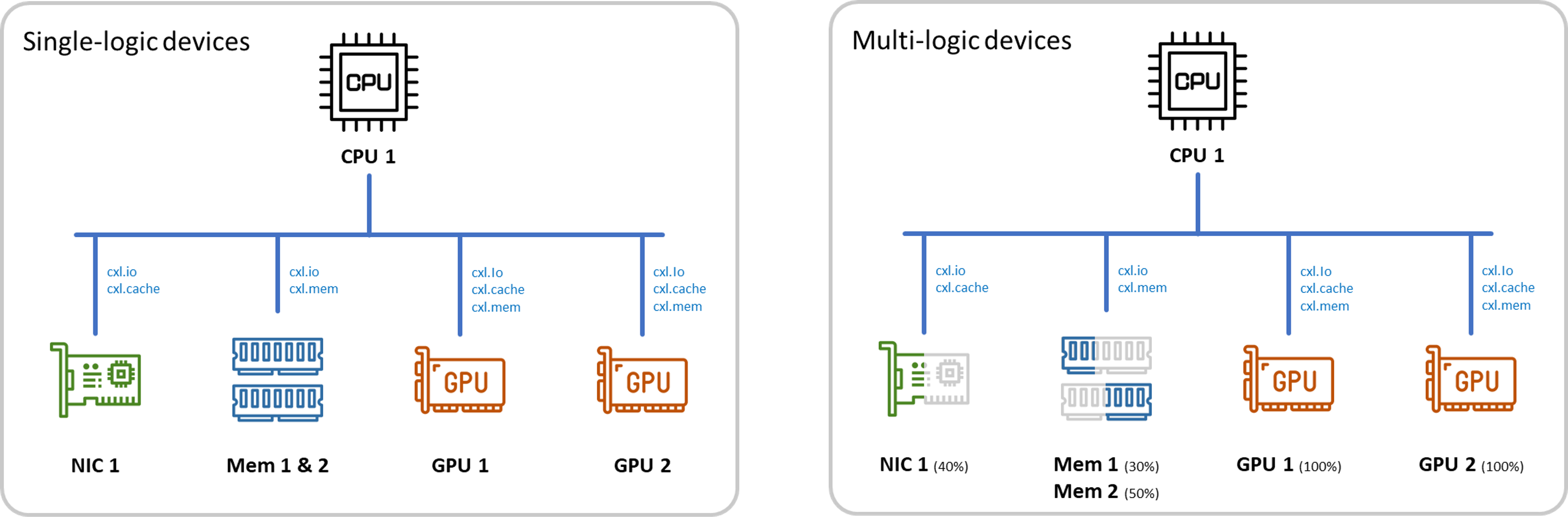
The switching capability in CXL 2.0 allows a multiple logic device (MLD) to be shared among multiple hosts. Putting these CXL 2.0 capabilities side by side with our Falcon 5208 NVMe MR-IOV solution, you would realize even more similarities between the two.
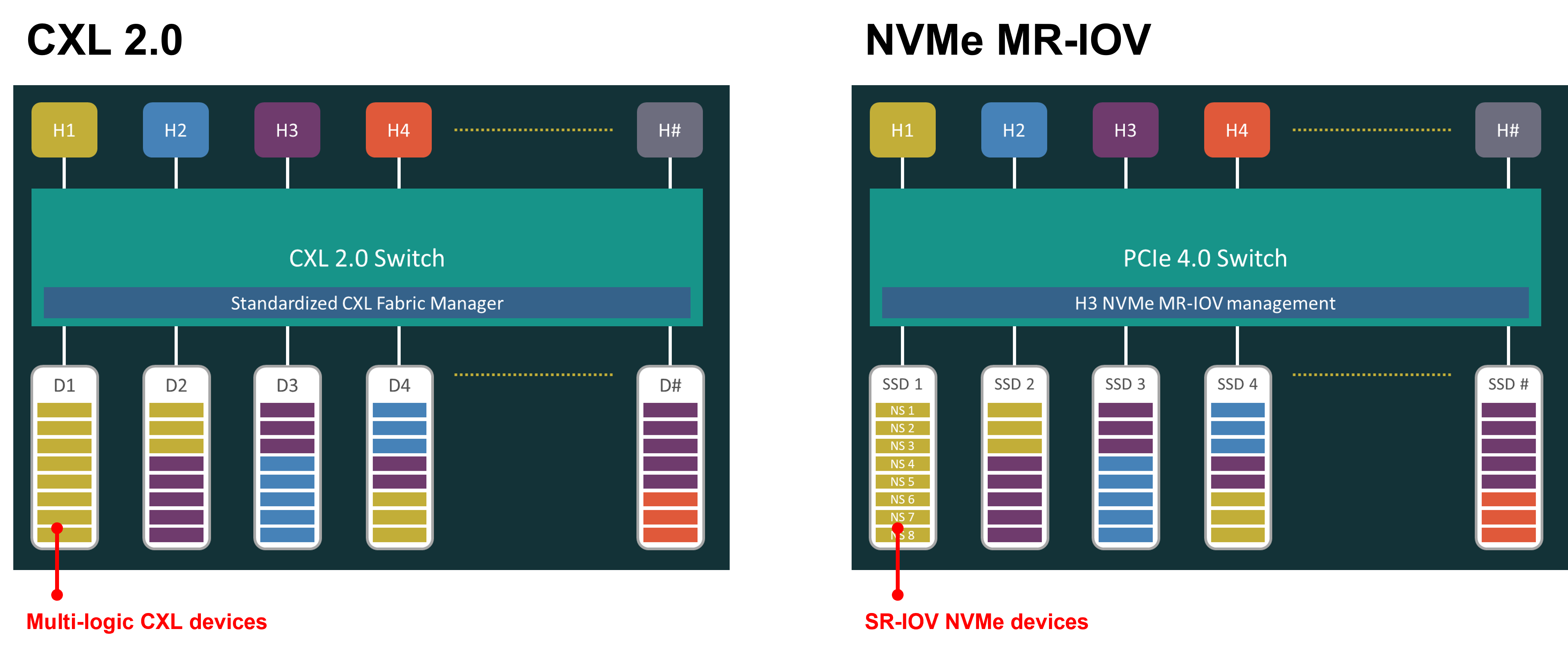
The H3 PCIe device management software servers pretty much the same function as the fabric manager in CXL 2.0. The fabric manager helps users to configure the devices, binding and unbinding resources to the hosts without interrupting ongoing applications.
Our storage expansion solution is currently based on PCIe Gen 4 and NVMe. However, in PCIe Gen5, CXL provides more possibility with higher bandwidth and lower latency. Not only storages, but also accelerators can be connected through CXL protocols, giving wide variety of peripheral resource pooling.
Compared to PCIe, CXL assures cache coherency between host CPUs and devices. Cache coherency improves compute efficiency in multi-processor environment. As the cached data being coherent, it eliminates much time and effort for the system to synchronize data between processors. The cache coherency would be the biggest advantage for future CXL device virtualization and multi-root applications, perhaps multi-root share of single-root IO virtualization using CXL protocols.
A composable CXL solution would have cache data being coherent between any CPU and peripheral devices of user’s choice. Also, the location of peripheral devices becomes less significant within rack level, enabling more efficient way for resources disaggregation.
CXL, being the next generation high-speed interconnect standard, perfectly aligns with H3 Platform’s product vision. With the past experience in PCIe switch, we are confident to incorporate CXL into our composable solutions in the future.
References:
https://www.rambus.com/blogs/compute-express-link/
https://www.techtarget.com/searchstorage/tip/How-the-CXL-interconnect-will-affect-enterprise-storage