Knowledge Base
On the orange area, the GPU is used in a traditional virtualized environment. It is also shared across multiple applications or users. The GPU virtualization solution is widely adapted in the existing infrastructure.









 x8
x8 x8
x8 x8
x8V_Server1

 x1x4x4
x1x4x4V_Server2
On the blue area, four key components are in a composable AI solution and these are the following: physical server, GPU chassis (GPU pool), PCIe fabric, and the management software. GPUs in GPU chassis are dynamically assigned to any connected physical server (through PCIe fabric) by management GUI or API to build up a composed server. GPU virtualization and composable AI solutions are complementary to each other.
P_Server1

P_Server2
GPU Pool
GPUs are installed in a GPU chassis. The host adapter (PCIe Gen4 x16) is installed in the PCIe slot of the physical server. A GPU chassis is connected to 2-4 physical servers via cables running the PCIe protocol.
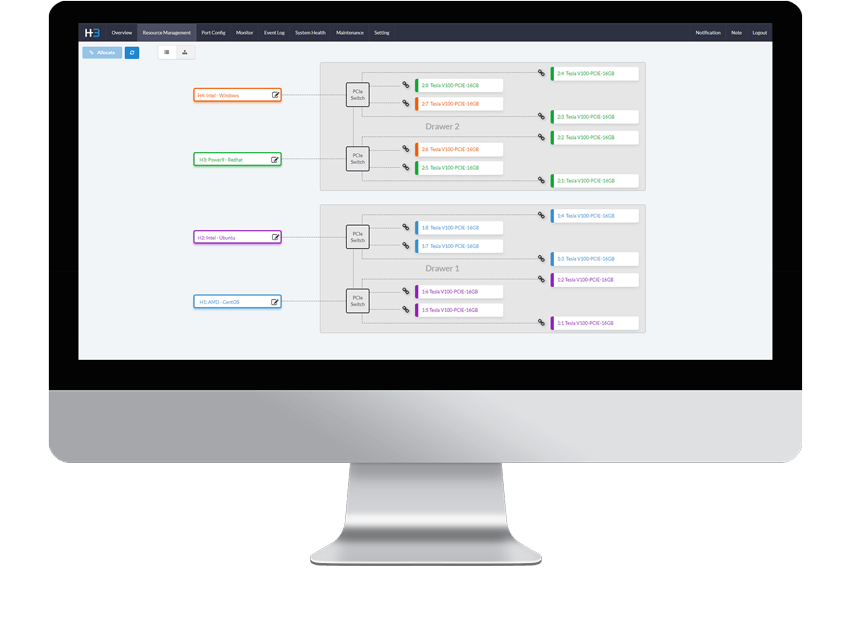
Users can use the management software of a single unit or H3 management center to assign (un-assign) a GPU to (from) a connected server.
Physical Server A
x40
PCIe cable
( PCIe 4.0 )
Physical Server A
x02
GPU Chassis
The composed server is composed by using a physical server and a GPU chassis. For example, if 2 GPUs in a GPU chassis are assigned to the first connected physical server, the composed server is a 2 GPU server (physical server plug 2 GPUs). These two GPUs are in a composed server work as direct-attached GPUs.
Composed Server
x2
Physical Server
x2
PCIe cable
( PCIe 4.0 )
GPU Chassis
Physical Server
x2
Users can use GPUs in composed servers as normal GPUs. In AI or HPC, GPUs are dedicated to one VM as bare metal GPU servers. In a virtual desktop or development environment, the GPU is shared across multiple VMs. This part is exactly the same as which GPUs are consumed in the existing infrastructure.
x8x8x8V_Server1
x1x4x4V_Server2
Management Software
Analytic Information
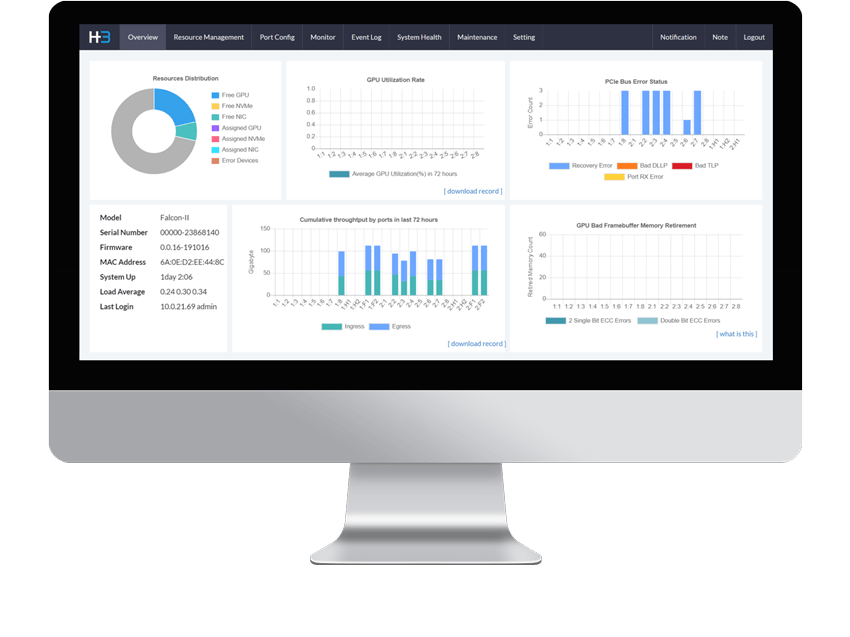
Through a graphic user interface, H3 Center enables GPU provisioning as well as GPU chassis discovery, inventory, port configuration, diagnostics, monitoring, fault detection, utilization auditing, and performance.
The IT administrator can provision or redeploy GPU and configure PCIe ports in just a few seconds without service interruptions.
H3 Center discovers the GPU utilization and performance then performs continuous real-time analysis to the administrator for better resource utilization.
H3 Center gives IT professionals the insight and control they need to manage and mitigate issues to anticipate failure risks. It also presents actions the administrator can take to anticipate and avoid problems.

Dynamically provision and scale GPU resources with greater flexibility and efficiency to maximize infrastructure value. Falcon 5012 is a disaggregated GPU solution built for generative AI, HPC, and data-intensive workloads. With support for up to 8 dual-slot GPUs and flexible host configurations, it enables on-demand GPU allocation across systems to reduce over-provisioning and improve utilization. This composable GPU architecture helps accelerate deployment, simplify resource management, and deliver scalable performance as AI workloads continue to grow.
Learn MoreIf you want to apply for any product display, please write a form and we will contact you after receiving the message.