Unleash the true power of AI compute
GPU-accelerated memory/storage is a new AI-native storage approach designed to keep pace with modern GPU scale. Instead of routing data through CPUs, it enables GPUs to pull data directly using massively parallel, low-latency access. By reducing CPU involvement, eliminating extra memory copies, and sustaining extreme IOPS and throughput, GPU-accelerated memory/storage improves GPU utilization and accelerates training, retrieval, and real-time inference workloads.

H3's GPU-accelerated memory/storage solution delivers ultra-high throughput and massive parallel I/O so GPUs stay fed with data—reducing stalls and accelerating end-to-end AI pipelines.
Improve GPU utilization and reduce wasted compute time by minimizing I/O bottlenecks, helping you generate more results per dollar spent.
Support many-to-many access between NVMe SSDs and GPUs, enabling efficient scaling across multi-GPU and multi-node deployments.
Offload data movement from CPU-driven paths and avoid unnecessary memory copies, improving system efficiency and stability at scale.
GPU-accelerated memory/storage moves data through a direct Storage → PCIe fabric → GPU path, avoiding CPU-mediated staging in system DRAM. This GPU-centric flow supports highly parallel I/O and low-latency transfers, keeping GPUs continuously fed with data for faster AI training and inference.
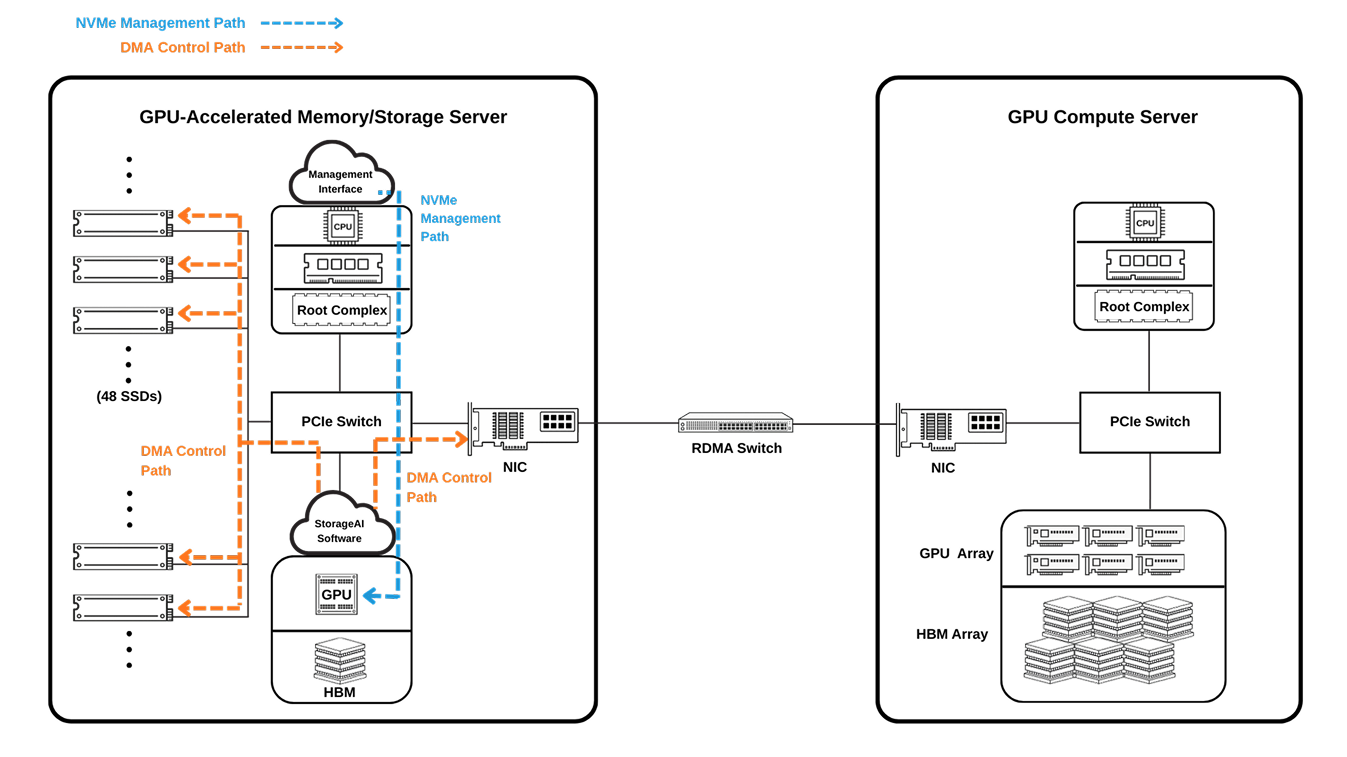
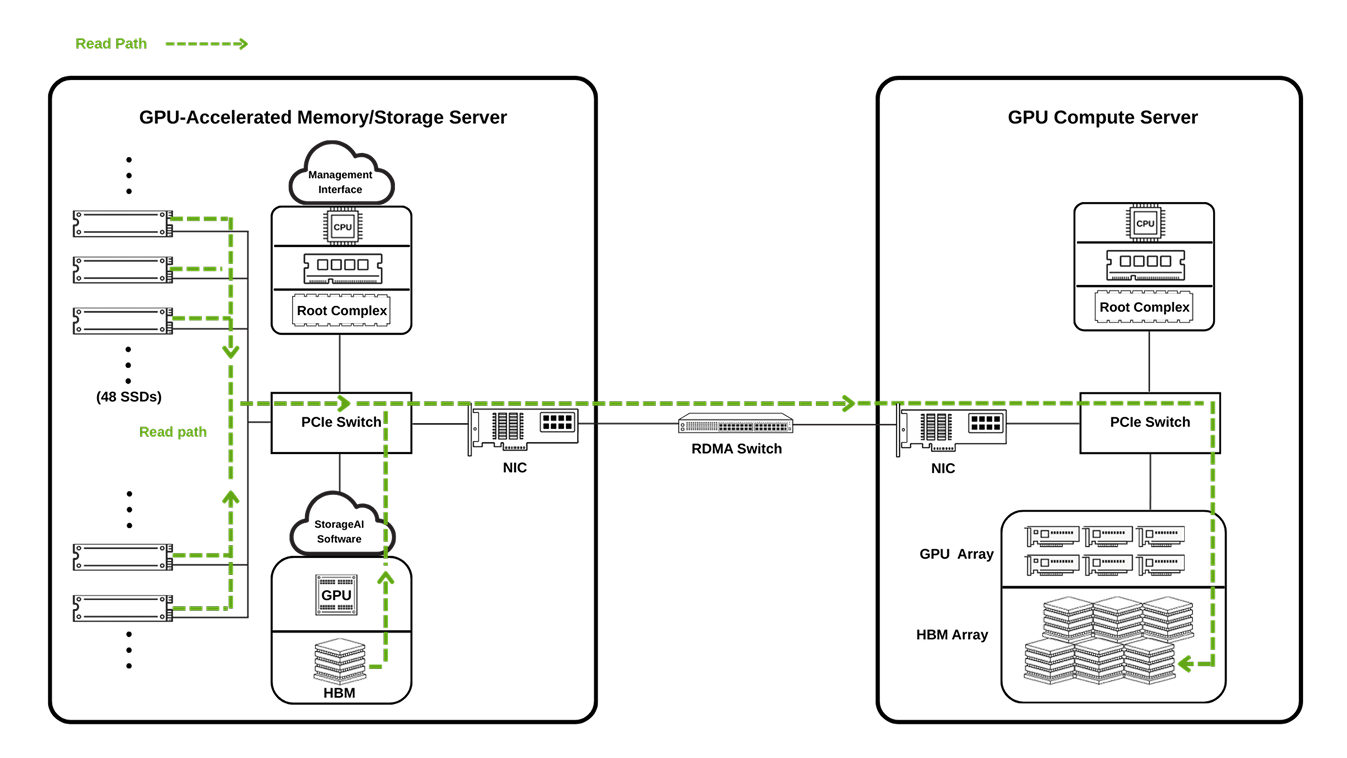
GNN power workloads like fraud detection and recommendation systems. They require highly irregular access patterns and millions of small reads to fetch graph features and neighbors. GPU-accelerated storage reduces I/O bottlenecks.
Vector databases enable semantic search and RAG by retrieving embeddings under high concurrency. GPU-accelerated storage speeds up embedding access and reduces data movement overhead for large-scale vector search.

Maximize the I/O throughput for your current AI infrastructure by enabling GPU-driven, highly parallel data access across NVMe storage. Reduce I/O bottlenecks, improve GPU utilization, and accelerate AI training, retrieval, and real-time inference—without rebuilding your entire system.