Knowledge Base
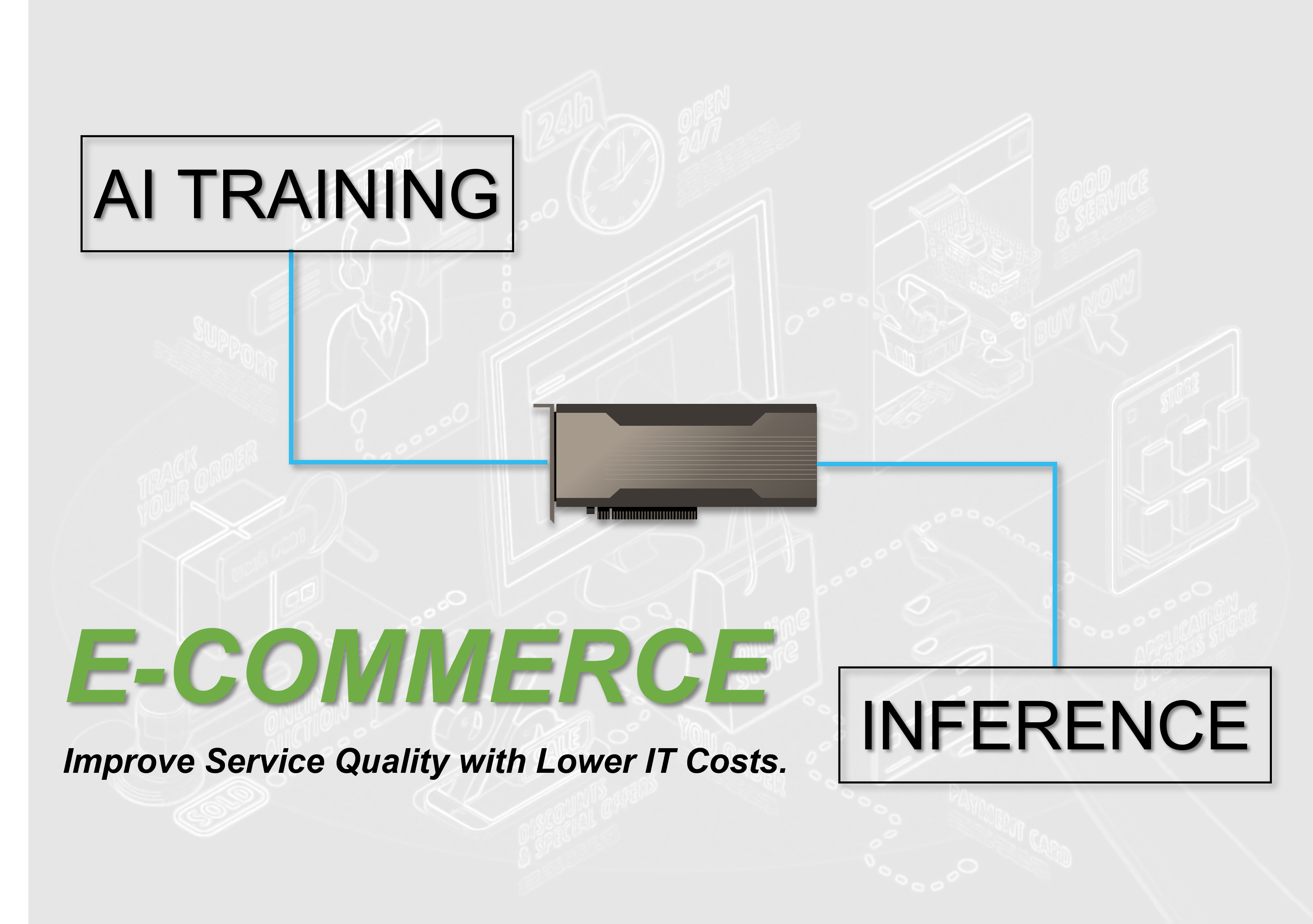
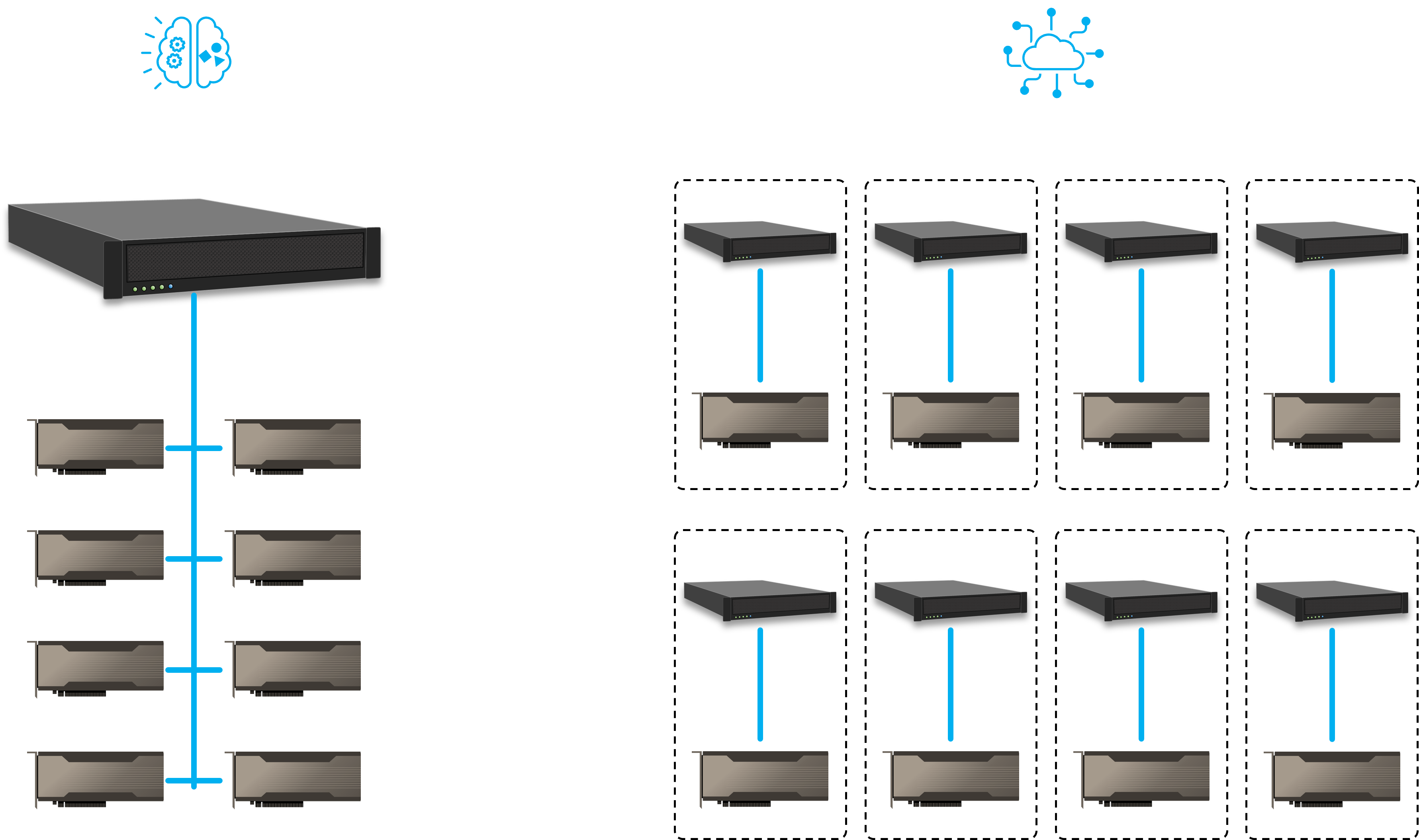
We currently acquired a client in e-commerce service industry. The client is planning to build a system that can meet its AI training and real-time inference requirements through dynamically allocating GPU resources. The entire system consists of 8 host servers and 8 NVIDIA A100 GPUs. One of the host servers possesses higher performance spec which can be used for AI training, the rest are dedicated to AI inference tasks. There is a PCIe switch fabric in the system to enable dynamic allocation of GPU resources.
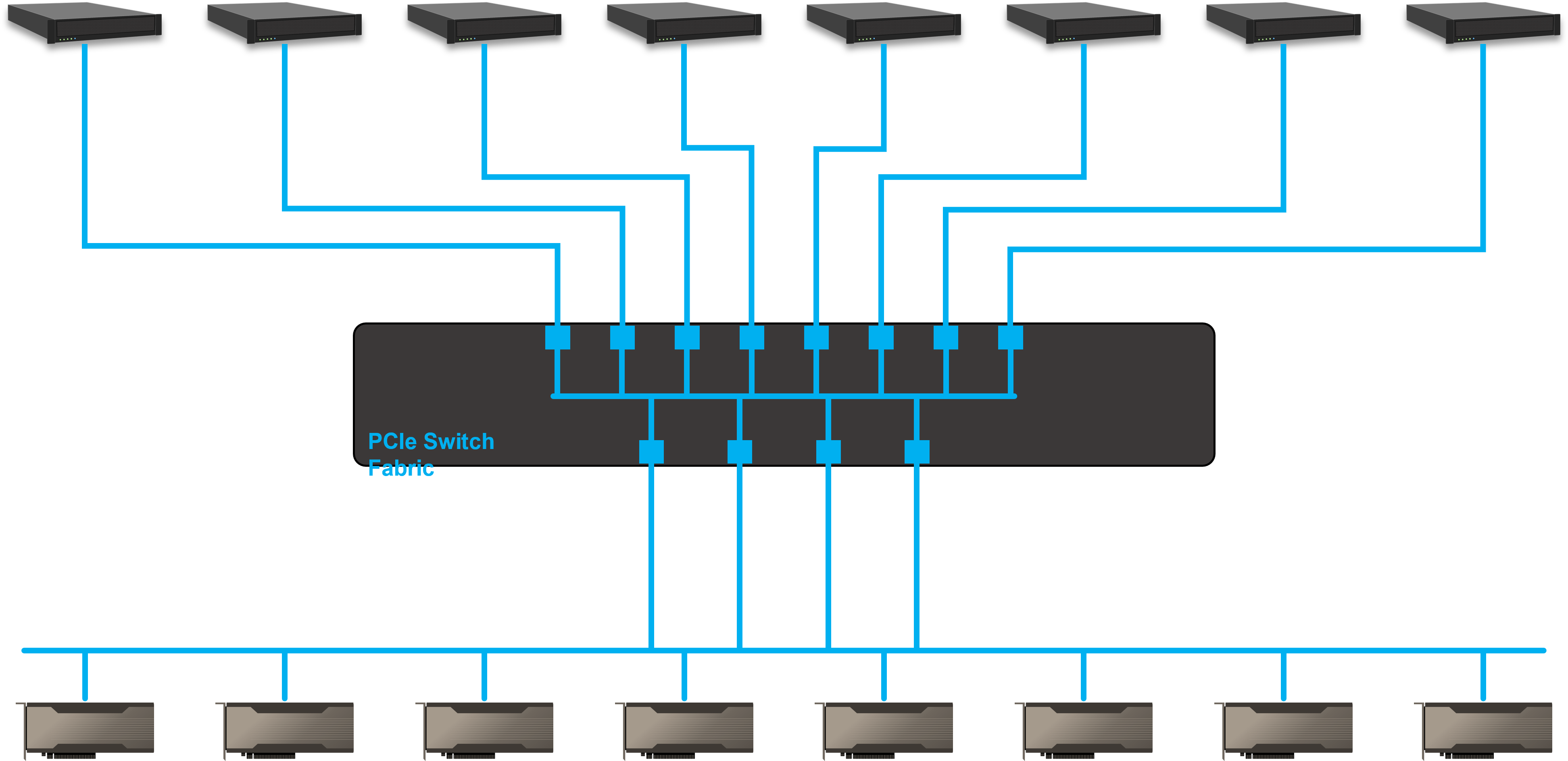
This client is planning to run its AI training and inference using the same set of GPU resource to maximize the value of its IT spending. The GPUs are equally distributed to each host server for real-time inference during peak hours. The company then re-train its AI model every day with newly collected data at the off-peak hours. All eight GPUs will be allocated to the host with higher spec for efficient AI training tasks. This way, the company can refine its AI model every day to improve the quality of its services.
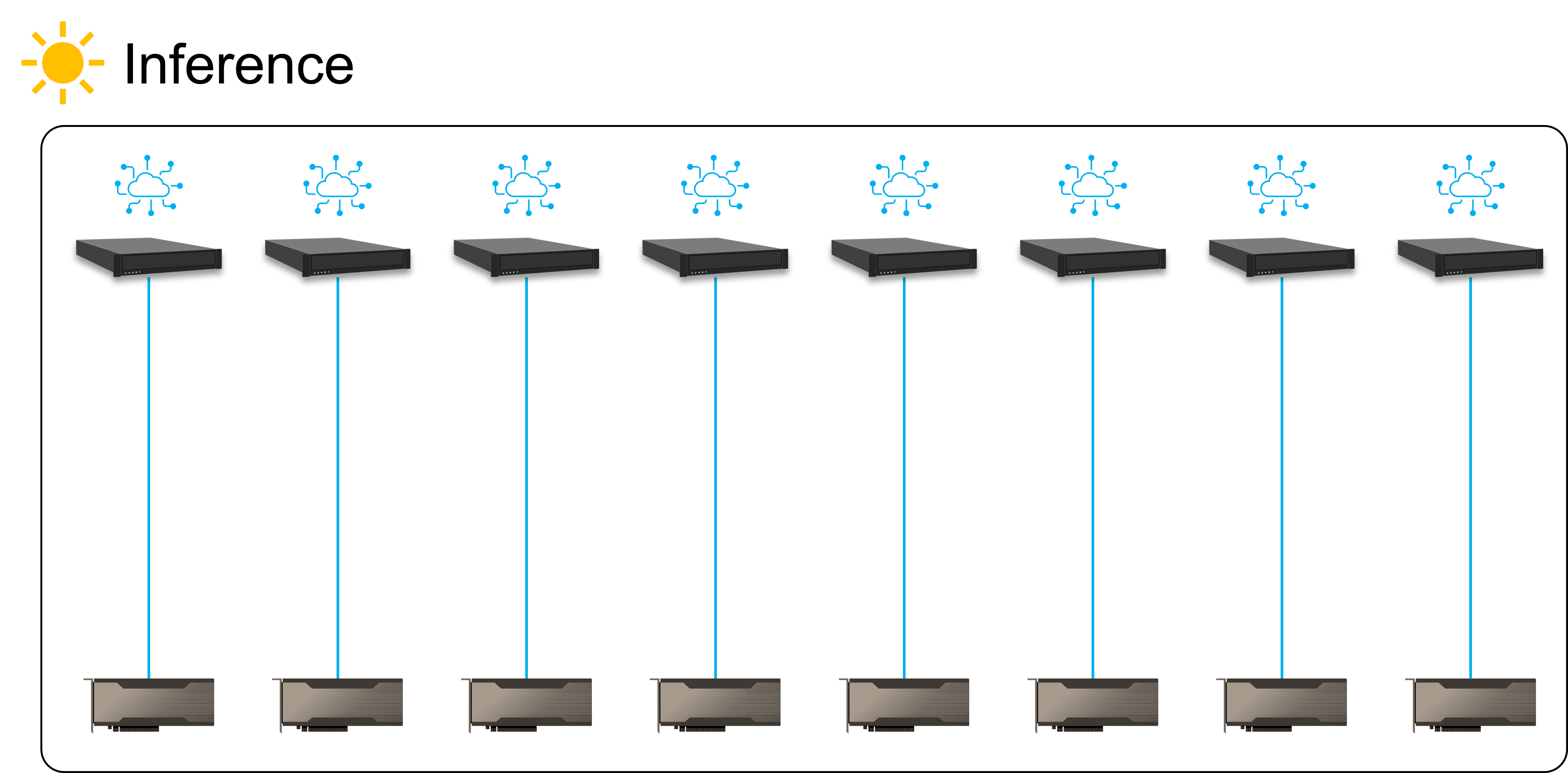
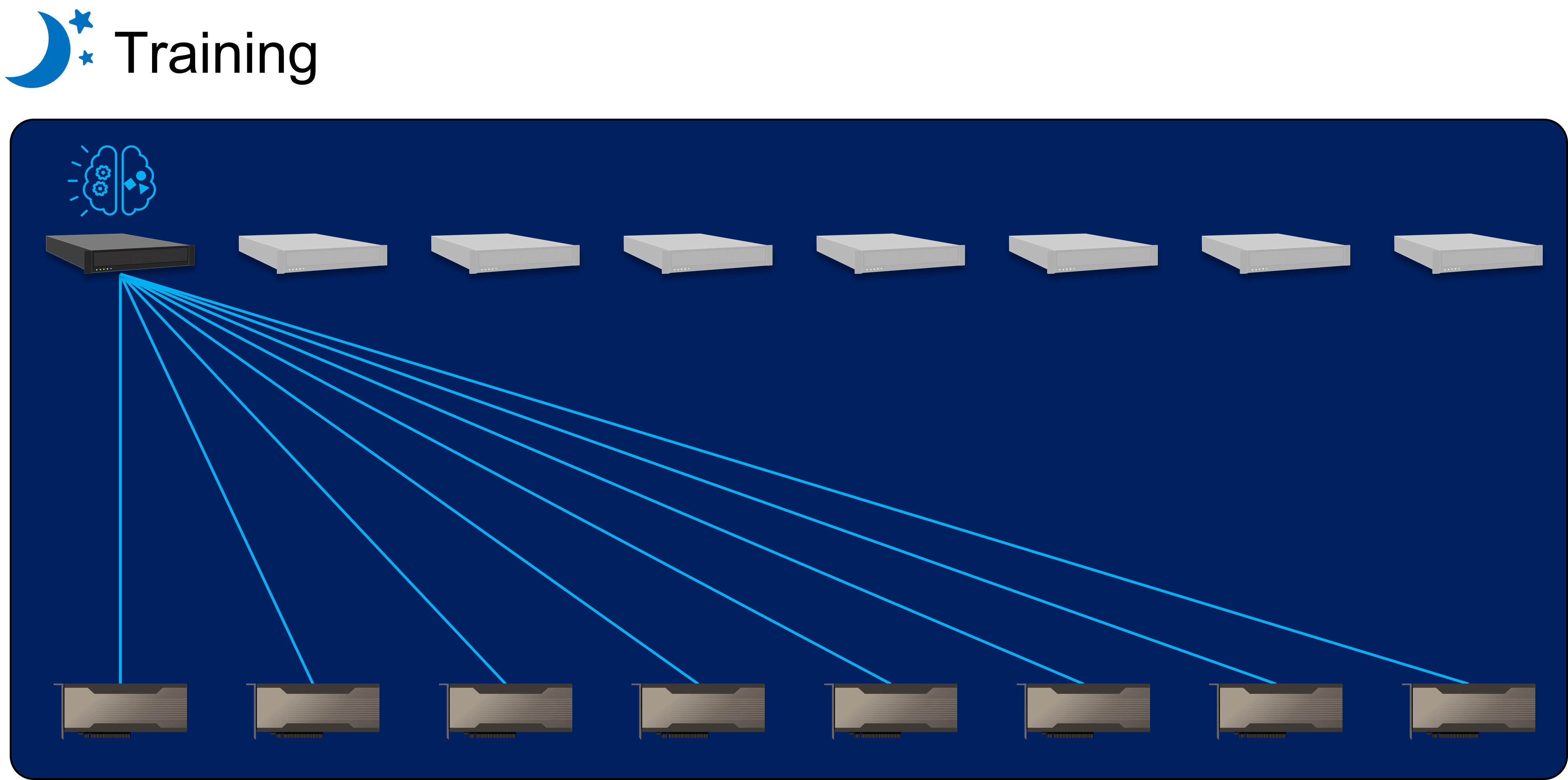
AI inference and training system are often separated due to the different spec requirement, however, having two separated systems would require much more IT equipment and can cause high device idle rate, resulting in inefficient IT resource usage.
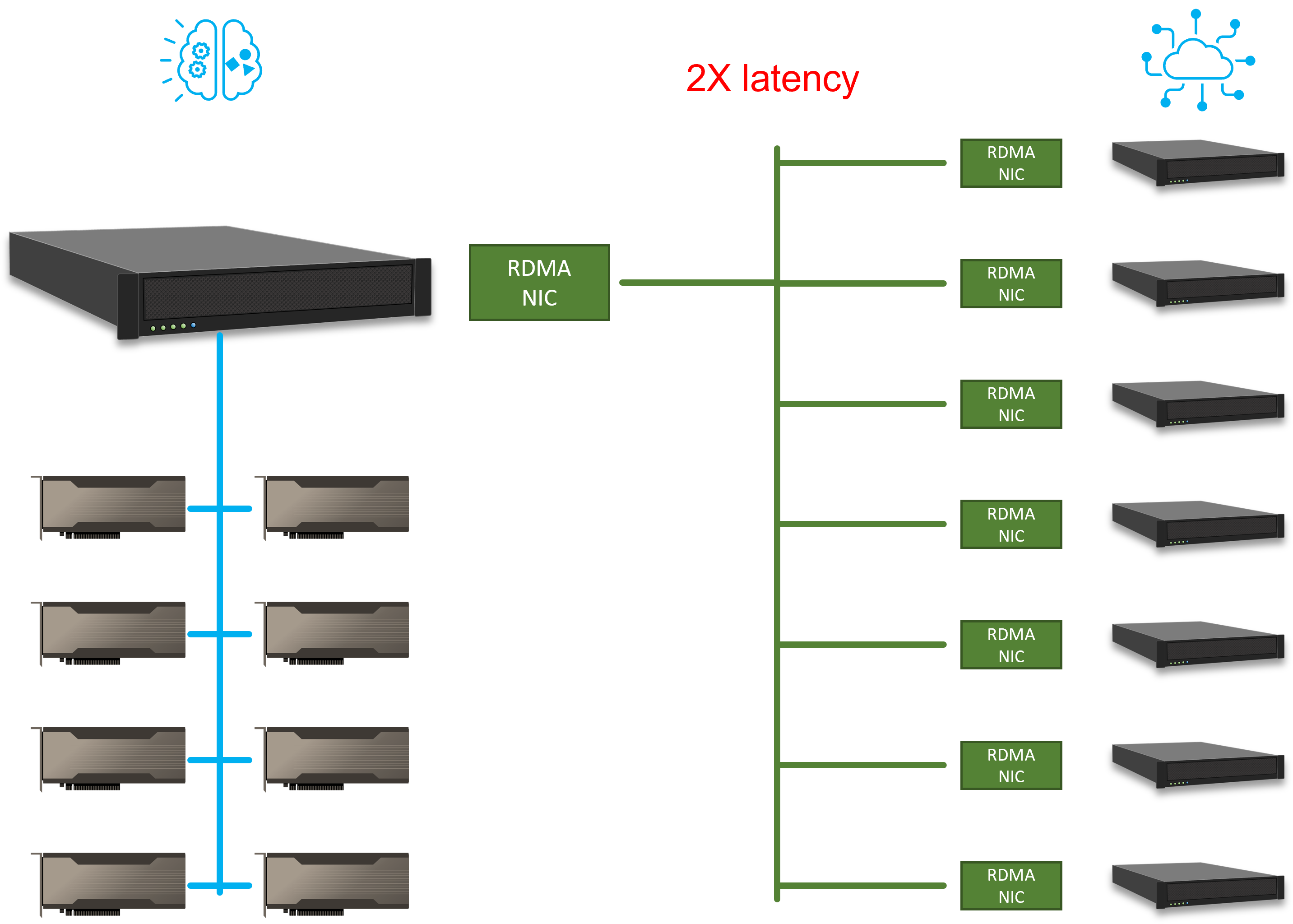
It is also quite often to see systems that allows access of GPUs through RDMA. RDMA allows the inference machines to access the same set of GPUs as the training machine. This way, the users can increase the utility of the expensive GPUs. However, the InfiniBand interconnection introduces extra transport abstraction layer which increases the overall latency to the system. GPUs are one of the most expensive computing devices in a system, being able to share GPU resources can significantly alleviate the high idle rate issue. Also, it means that less GPUs are needed thus driving the system cost down.
Comparing to the RDMA architecture, the PCIe fabric allows data to transfer between GPU and inference machines without protocol change. PCIe has latency measured in nanoseconds, and this can significantly improve the responsiveness of real-time inference while reducing the GPU units needed. In other words, not only the hardware cost is cheaper, but also it requires shorter time for the system to figure out what information should be pushed to the target customers.
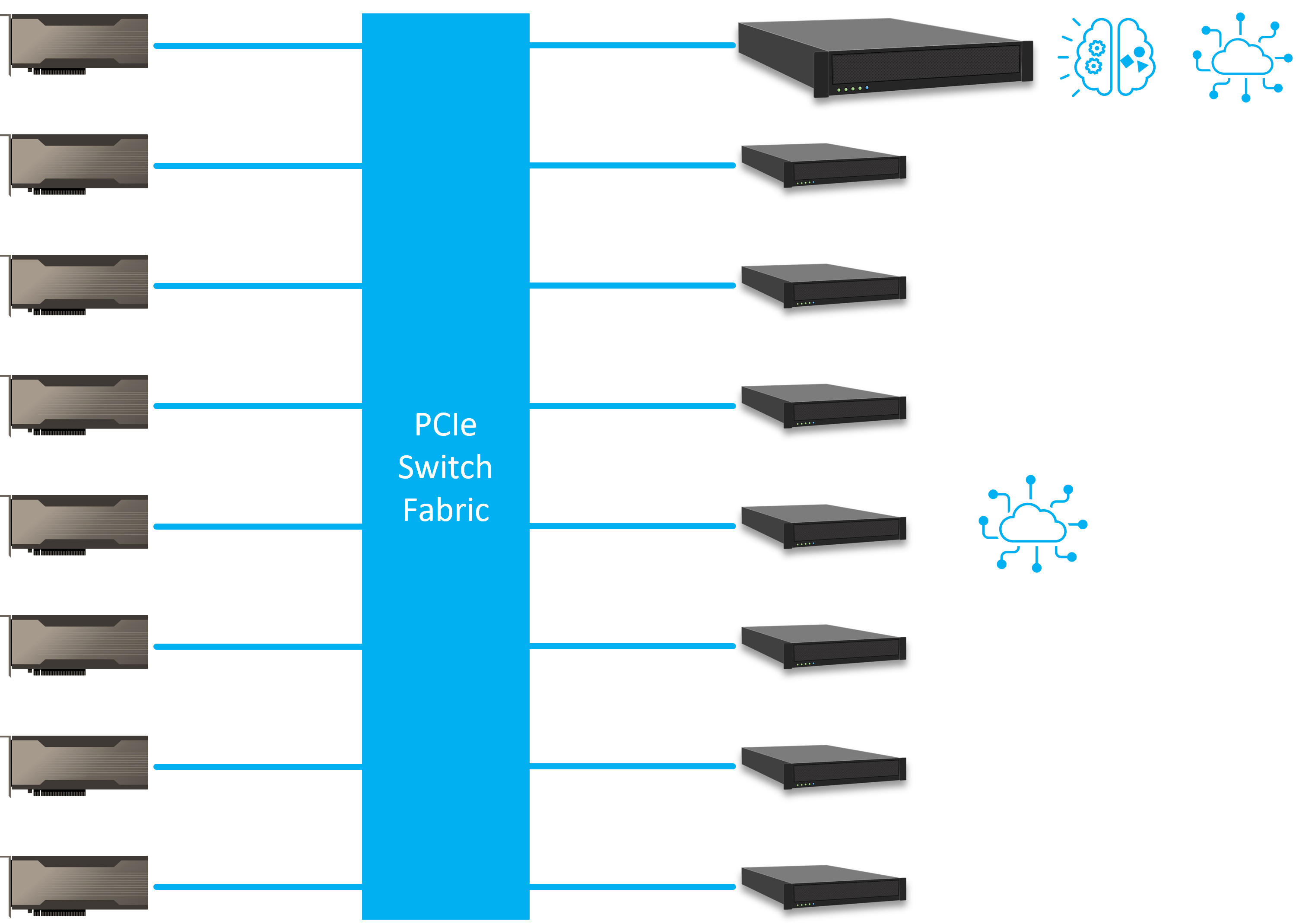
The GPUs in this system are software-defined. With the H3 Platform’s management API, users can monitor the performance every GPU device as well as re-allocating the GPUs remotely, giving users a cloud like experience. This software defined GPU system introduces great flexibility to the IT resources.
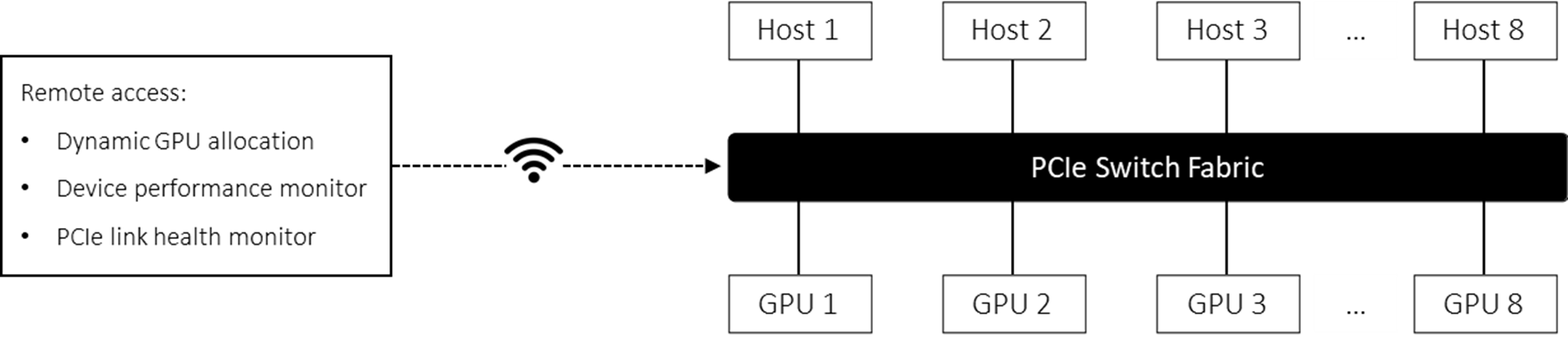
Following the release of more powerful GPU hardware, the overhead caused by interconnection on system performance would become more and more significant. PCIe perhaps is the most economically efficient way to overcome this emerging issue in modern HPC systems. In addition, the composable architecture not only reduces overall system cost, but also helps businesses to better response to the changing environment and improve service quality by meeting any computing requirement at any point of time.