Knowledge Base
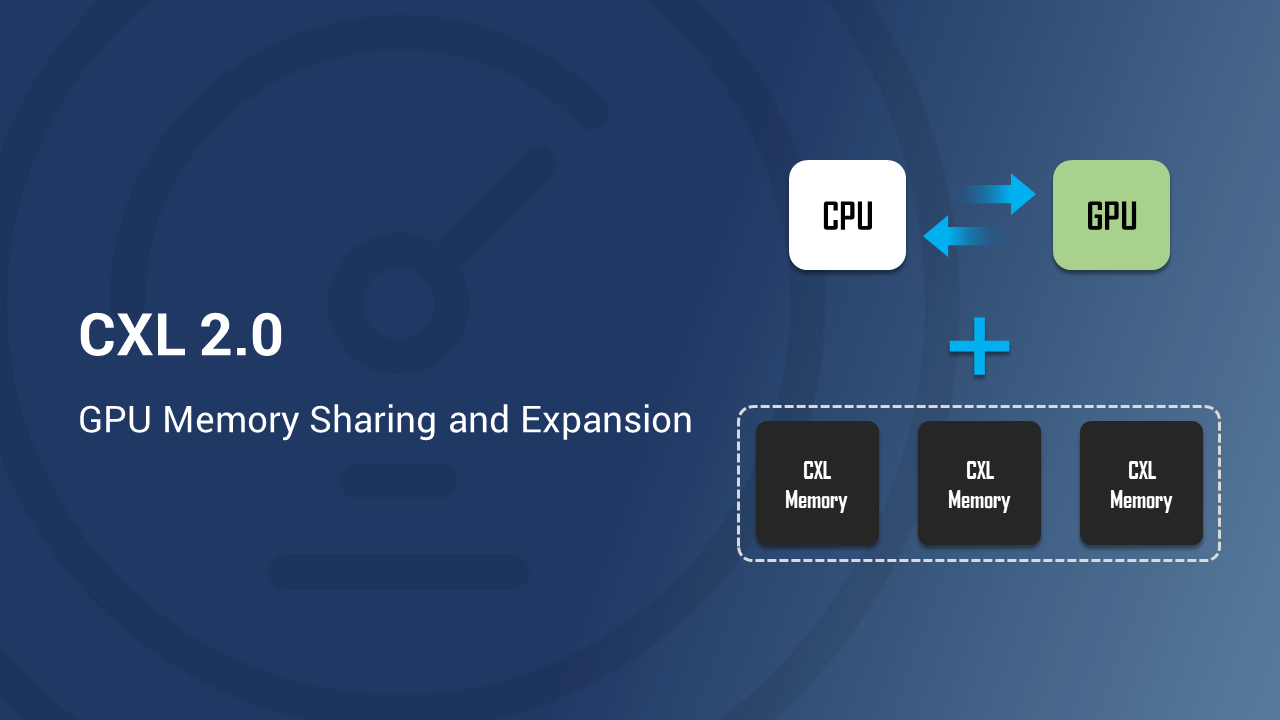
CXL memory have been widely discussed for its capability to enhance memory bandwidth and capacity, and these benefits are significant to the emerging AI/ML applications. Aside from memory, the CXL specification also includes accelerators. As we have not seen much discussion on CXL accelerators, and with our experiences in PCIe switches, we decided to share some thoughts on CXL2.0 and the disaggregated architectures that incorporates not only memory but also accelerators.
Under CXL specification, a memory expander is classified as a “type 3 device”. The GPGPUs that has device-attached memory would be “type 2 devices”. A memory expander is straight forward, it’s only purpose is to provide more memory to the CPU, be it volatile (i.e., DDR) or non-volatile (i.e., persistent memory), there isn’t cache coherence issue with CXL memory, the host CPU simply access the media through CXL.mem protocol. Nonetheless, an accelerator is much more complex. Cache coherence is critical in heterogeneous computing, and CXL helps to maintain cache coherency between multiple processors and the accelerators thorugh the CXL.cache protocol.
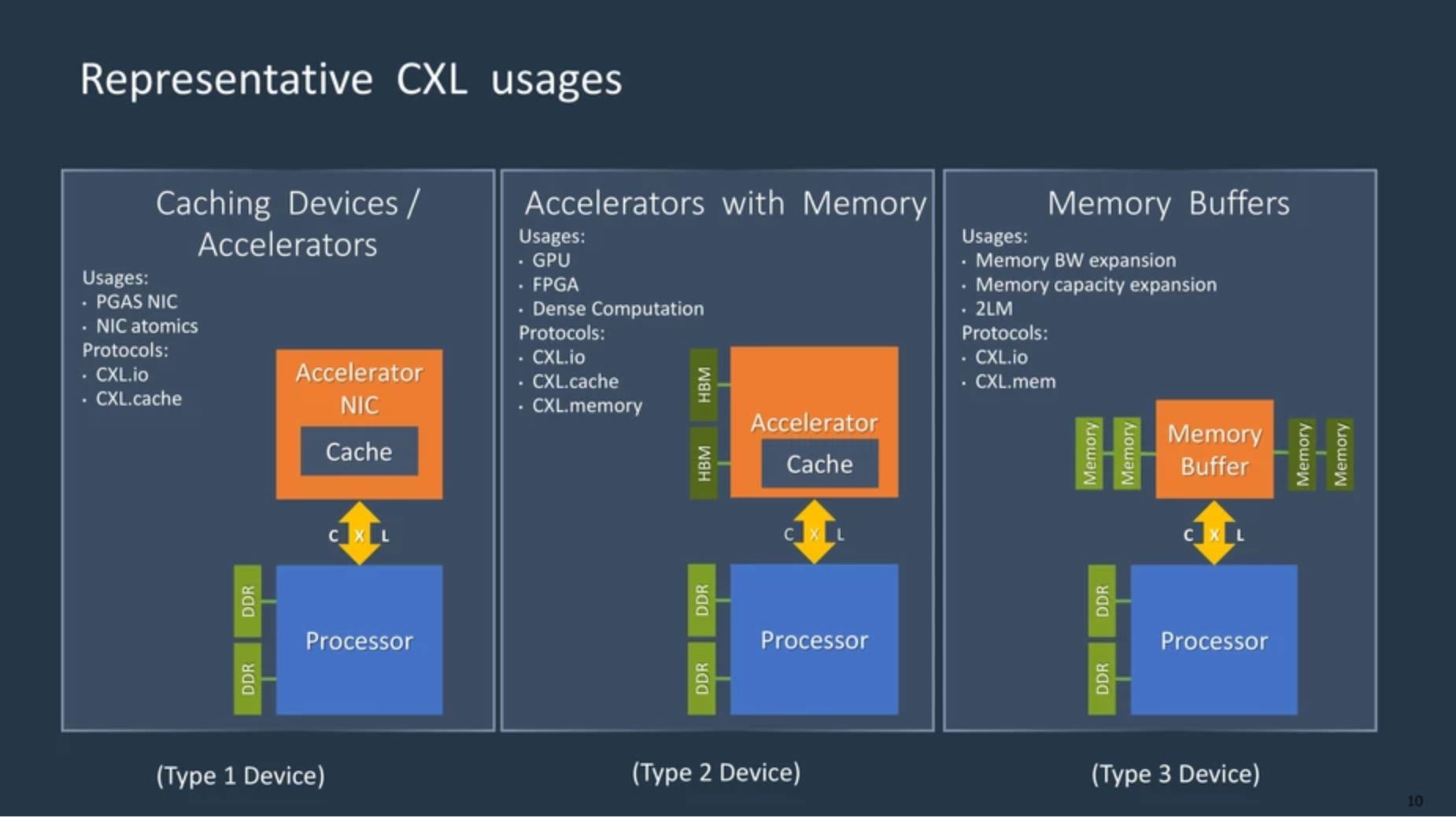
Image from https://www.computeexpresslink.org/
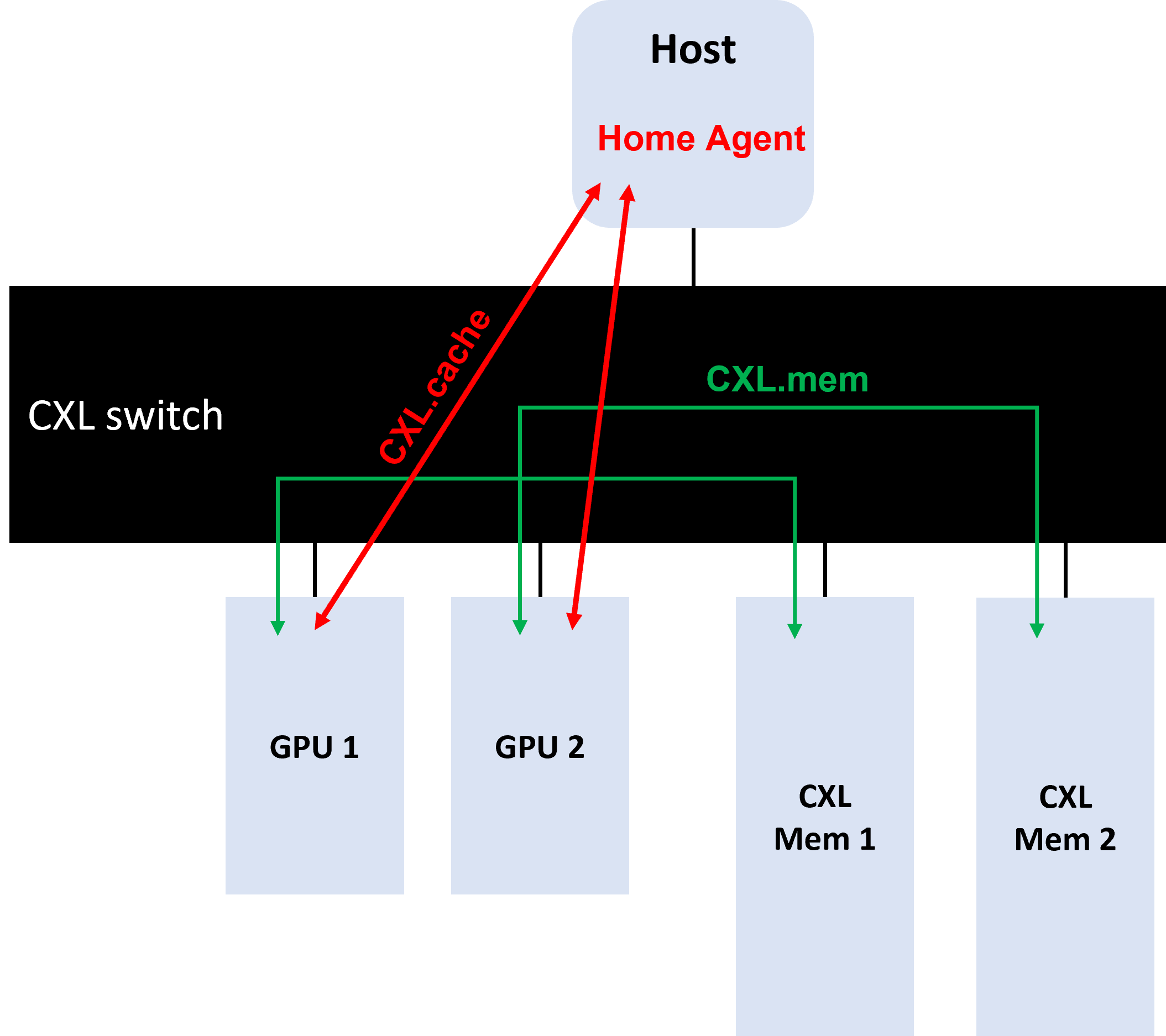
If we put a CXL GPU (type 2 device) and a CXL memory expansion module (type 3 device) under the same CXL fabric that is connected to a CPU serving as the home agent, we can expect that the GPU is able to access data directly from the memory module through cxl.mem protocol. On the other hand, if 2 CXL GPUs are put under the same CXL fabric, we can expect that the two GPUs communicating peer to peer through cxl.mem and maintaining cache coherence with cxl.cach protocol by a home agent CPU.
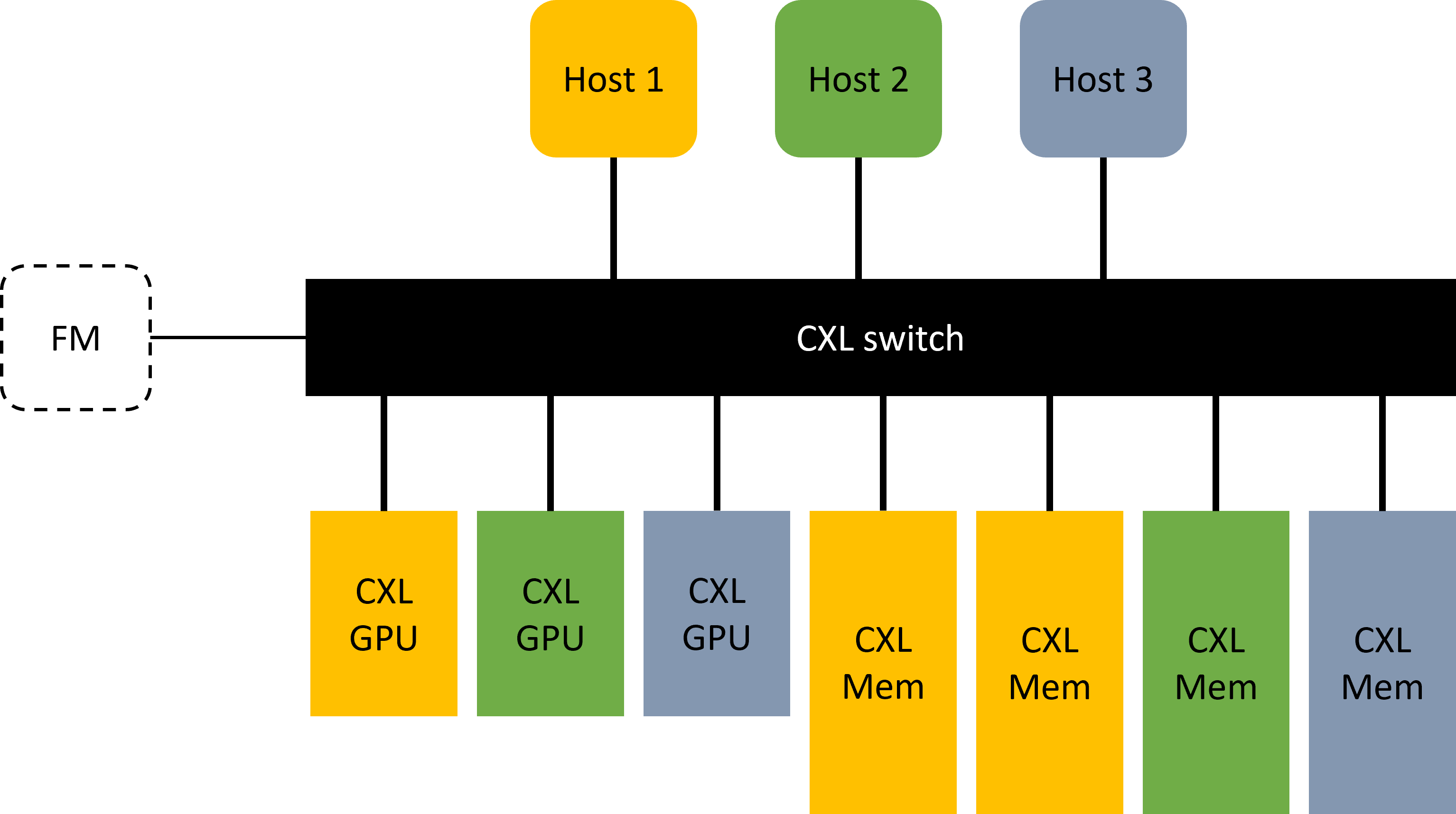
Within the system, users can compose cache coherence domain of any size. For example, host 1 in the illustration is in color yellow, and the memory module and GPU assigned to host 1 are also indicated in yellow. Now, host 1 CPU will serve as the home agent and maintains cache coherence between host 1 and the GPU and memory module assigned to it. While Host 1 forms a cache coherence domain, host 2 and host 3 can be used to form different cache coherence domain.
Now let’s extend it a little further, what if the GPUs could directly fetch data from the CXL memory? Currently, NVIDIA’s CUDA allows GPUs to access certain portion of host memory as their own memory, and CXL memory can be used to expand host memory. So, the GPU should be able to recognize the CXL memory as the host memory without a problem, and the host should be able to allocate a portion of the CXL memory to the GPU devices, creating a direct path for the GPUs to access the CXL memory using the cxl.mem protocol.
The article CXL: Simplifying server, written by Siddharth Bhatla, discussed that “Scaling the server memory beyond a point becomes less attractive when using the DDR or HBM memory (due to physical, power and cost limitations).” With CXL, the PCIe attached DRAM is able to give byte-level memory access to CPU just like the DDR DRAMs. While it benefits CPU memory expansion, is it possible to apply the same concept to GPUs?
The NVLink was introduced by Nvidia to allow combining memory of multiple GPUs as a larger pool. Now, with CXL memory expansion, we can further extend the amount of memory that GPU has, exceeding the limitation of on-GPU memory physical, power and costs. We thought this is possible because according to CXL.org, a CXL type 1 or 2 device is able to target memory in peer CXL device as long as the target device supports the CXL.mem protocol. In the context of memory expansion, CXL does not specify that a home agent is necessary. Nonetheless, the cache coherence between CXL GPUs is still managed by a CPU home agent.
A good outcome of using CXL though, is that it allows processors to send direct read/write commands to media and does not require doorbells or interrupts (like DMA), meaning that the latency can be further reduced. So, if GPUs are able to fetch data directly from CXL memory without much performance drop, we can allocate any amount of memory to the GPUs and wouldn’t have to worry much about data batch size for training efficiency when designing our AI models or any similar applications.
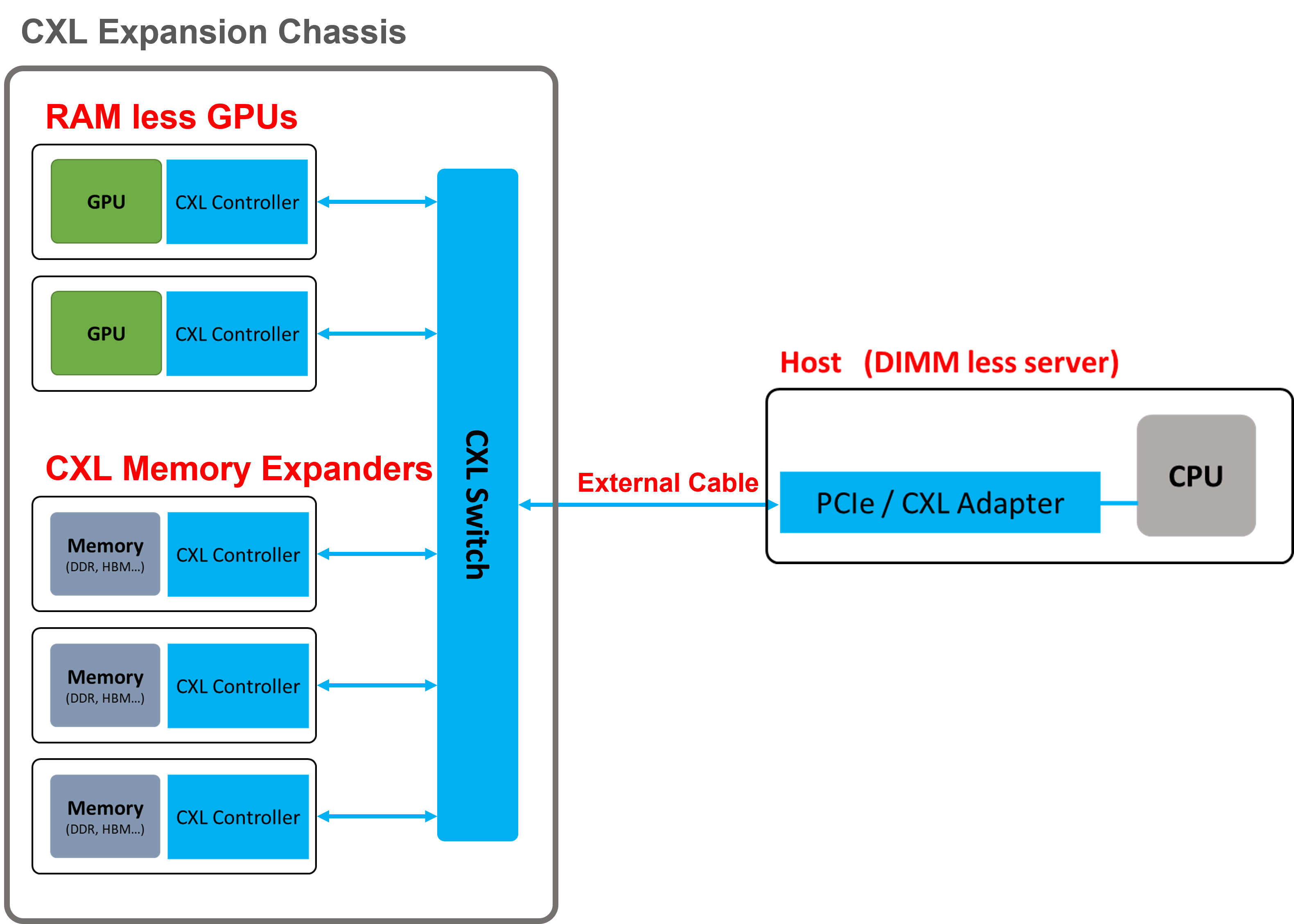
As we all have known, CXL leverages PCIe gen 5 physical layers, and the performance is still a bit lesser than the direct-attached DIMMs. As a result, the DIMMs local to CPU sockets are still significant to current computing architectures. Maybe we would see servers without DIMM slots, or accelerators devices without RAM soldering on it as CXL memory expansion technology evolves.
https://dl.acm.org/doi/fullHtml/10.1145/3533737.3535090
https://www.computeexpresslink.org/post/__q-a
https://www.counterpointresearch.com/cxl-simplifying-server-fabric/