The landscape of artificial intelligence is undergoing a profound transformation, driven by the exponential growth
of complex workloads such as large language models (LLMs), vector search, and graph neural networks (GNNs).
While GPUs have advanced rapidly—delivering unprecedented computational power—the real limiter for AI systems
has shifted from compute to data movement.
The bottleneck in today’s AI systems is no longer compute – It is storage.
More specifically: the speed at which storage can feed data to GPUs.
Traditional storage systems, designed for less demanding tasks, are now struggling to keep pace with the immense
data requirements of modern AI, leading to performance limitations that hinder progress and efficiency.
In this article, you'll find:
1. GPU Starvation: When GPUs Wait Instead of Compute
Modern GPUs such as NVIDIA’s H100 and H200 are engineered for extreme throughput, capable of trillions of operations
per second, hundreds of gigabytes per second of memory bandwidth, and highly optimized matrix execution paths.
Yet even the most powerful GPU becomes ineffective when starved of data. Enterprise NAS or SAN systems typically
exhibit millisecond-level latency, tens of thousands of IOPS, and only a few gigabytes per second of
throughput—orders of magnitude slower than what GPUs require.
This mismatch creates a widening performance gap:
GPU speed (TB/s) ≫ Storage speed (GB/s → MB/s)
As a result, GPUs often spend 30-60% of their time idle,
unable to process data quickly enough to maintain parallel compute efficiency. This phenomenon, known as
GPU starvation, has become a central motivator for rethinking storage infrastructure in the AI era.
2. Why Traditional Storage Cannot Handle AI Workloads
Traditional storage architectures such as NAS, SAN, and HDD-centric systems were designed for a fundamentally different
computing paradigm—one based on capacity, redundancy, durability, and multi-tenant access over Ethernet.
These design priorities serve business applications well, but they fundamentally conflict with the highly parallel,
low-latency needs of AI.
Traditional storage fails to keep up with AI workloads due to:
- Network-based latency and jitter that slow GPU delivery
- Insufficient IOPS, often capping at ~100K under real workloads
- Controller bottlenecks in RAID/SAN architectures
- Poor small-file performance, causing metadata-driven delays
- CPU involvement, which adds overhead and constrains data paths
AI pipelines frequently involve thousands of small files, metadata-heavy operations, or parallel GPU access
patterns that overwhelm legacy systems. It is not that traditional enterprise storage is flawed—it is simply
optimized for sequential or block-based access, not the microsecond-latency, GPU-centric
data paths AI workloads now require. The result is slow pipelines, bottlenecks, and significant underutilization
of expensive GPU resources.
3. The Architecture Shift: from CPU-Polling to GPU-Polling Data transfer
Legacy storage follows a CPU-centric data path:
Storage → Network → CPU → PCIe → GPU

This CPU-centric design introduces inefficiencies at multiple points, as the CPU acts as an intermediary, processing
requests and moving data between storage and the GPU. Two main bottlenecks are:
- Data must pass through the CPU
- Network bandwidth becomes the ceiling
In contrast, AI systems increasingly adopt GPU-centric, direct data paths:
NVMe → PCIe Switch → GPU (direct)
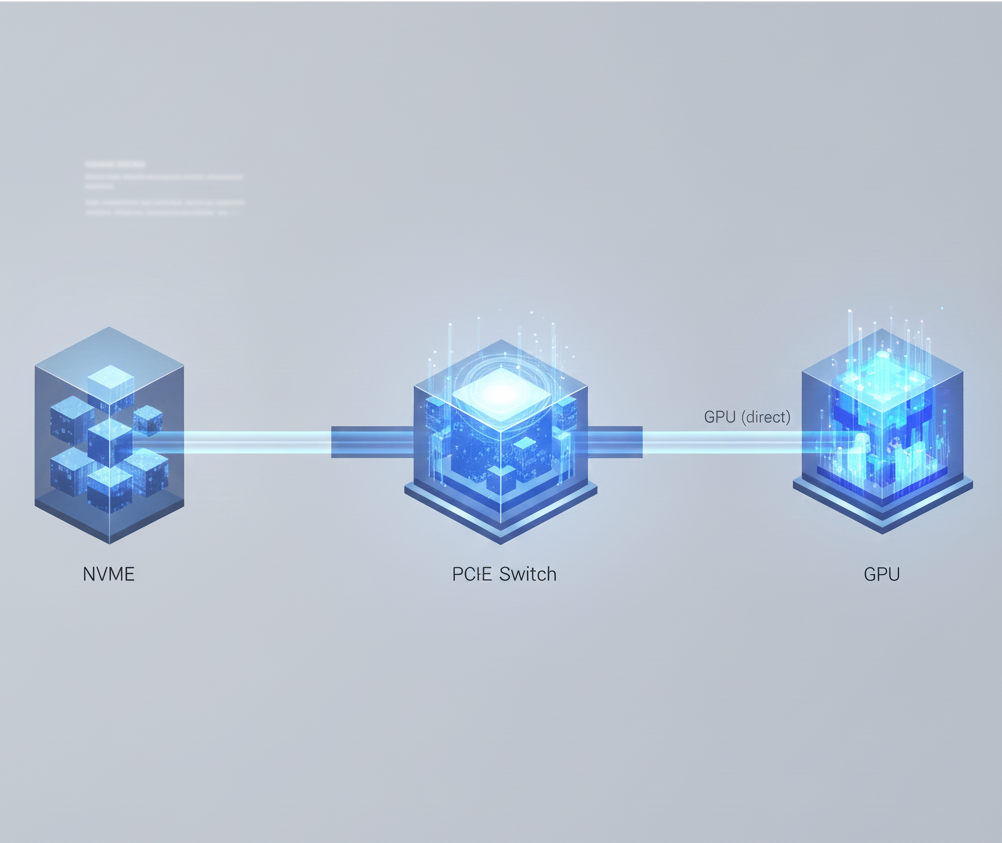
This architecture bypasses the CPU bottleneck, significantly reducing latency and maximizing data throughput. It's not merely about making components faster; it's about re-architecting the entire data path to accommodate the GPU's demand for data, ensuring the architecture itself is optimized for AI's unique computational model.
4. AI Workloads Are Data-Hungry by Design
AI workloads are inherently data-hungry because their massively parallel computations rely on a continuous,
high-speed flow of information to keep GPUs operating at full capacity. This demand appears across every stage
of the pipeline.
Large-scale training datasets:
LLMs and vision models require petabytes of data. During training, these datasets are repeatedly streamed to GPUs at
very high throughput. Any lag directly slows down model convergence.
Random small-block I/O:
AI preprocessing and vector search involve millions of small, random reads—far beyond what NAS/SAN systems are
optimized for.
Massive checkpoint writes:
Training large models requires frequent checkpointing of 100–800 GB per snapshot, pushing write throughput and latency to
their limits.
Real-time inference pipelines:
Recommendation engines, vector databases, and retrieval systems all require low-latency access to embeddings and graph
structures.
Together, these patterns—massive sequential reads plus extreme random I/O—are fundamentally incompatible with the design
assumptions of traditional RAID/NAS/SAN systems, which expect mostly sequential workloads with occasional
bursts.
5. AI Is Changing the Definition of Storage Itself: from Memory load/store to Data pump
As enterprise adoption of AI accelerates, the role of storage is shifting dramatically from
a passive data repository to an active participant in the AI pipeline.
In modern AI systems, storage is no longer just “where data sits.” It is part of the computation flow—responsible
for:
- Streaming training datasets
- Serving embeddings
- Enabling fast retrieval and search
- Supporting graph computations
- Providing memory-like access through CXL
- Offloading CPU via GPU-accelerated I/O
This new role requires storage systems designed from the ground up for AI workloads—not retrofitted versions of
legacy architectures.
6. Conclusion — A New Category of Storage for AI
AI’s rapidly expanding data demands make it clear that traditional storage is no longer adequate. Modern AI workloads
require architectures engineered for microsecond latency, massive parallelism, and direct GPU data paths. As the
industry shifts toward GPU-accelerated and AI-native storage solutions, it is evident that next-generation
performance will rely on infrastructures purpose-built to sustain the speed, volume, and complexity of AI. The
future of high-performance computing—and AI innovation—depends on storage designed from the ground up for the
unique requirements of AI workloads.
7. FAQ
1. Why is storage now the bottleneck in modern AI systems?
GPUs operate at terabyte-per-second speeds, while traditional NAS/SAN storage delivers only gigabytes per second with
millisecond latency. This huge mismatch prevents GPUs from receiving data fast enough, making storage the
primary performance limiter in AI pipelines.
2. What is GPU starvation, and why does it matter?
GPU starvation happens when GPUs wait for data instead of computing. Slow storage causes long idle periods, reducing
utilization and increasing the cost and duration of AI training.
3. Why can’t traditional NAS/SAN storage support AI workloads?
Traditional storage emphasizes capacity and durability, not parallelism or latency. It suffers from network delays, limited
IOPS, controller bottlenecks, and poor small-file performance—making it incompatible with AI’s random,
high-speed, GPU-centric I/O patterns.
4. What makes AI workloads uniquely demanding on storage?
AI workloads involve massive dataset streaming, millions of random small reads, large checkpoint writes, and
real-time embedding lookups. This mix of huge sequential I/O and extreme random I/O exceeds what traditional
RAID/NAS/SAN systems can handle efficiently.
5. How does GPU-centric architecture improve AI storage performance?
GPU-centric paths like NVMe → PCIe Switch → GPU bypass CPU and network bottlenecks. This reduces latency,
increases throughput, and delivers data directly to GPUs at the speed required to keep modern AI clusters fully utilized.
