Knowledge Base

The relentless pursuit of performance in modern data centers has led us to an era of unprecedented computational power, yet it's simultaneously exposing a critical bottleneck: stranded memory. As processing demands for AI, big data analytics, and high-performance computing continue to surge, traditional server architectures struggle to keep pace. This often results in valuable memory resources sitting idle within individual servers, unable to be shared or reallocated, leading to significant cost inefficiencies and stifled innovation.
Witnessing this challenge firsthand, IT leaders are seeking transformative solutions that can unlock the full potential of existing hardware. Enter CXL (Compute Express Link) Memory Sharing architecture, a revolutionary approach that breaks down the rigid boundaries of monolithic servers. By enabling disaggregated nodes to dynamically share memory resources, CXL ushers in an age of composable infrastructure, where compute, memory, and accelerators can be fluidly orchestrated to precisely match workload requirements.
Leading this charge is the H3 Platform's Falcon C5022, a cutting-edge solution designed to harness the power of CXL memory Sharing, offering a pathway to enhanced resource utilization, reduced total cost of ownership, and the agility needed to power the next generation of data-intensive applications.
In this article, you'll find:
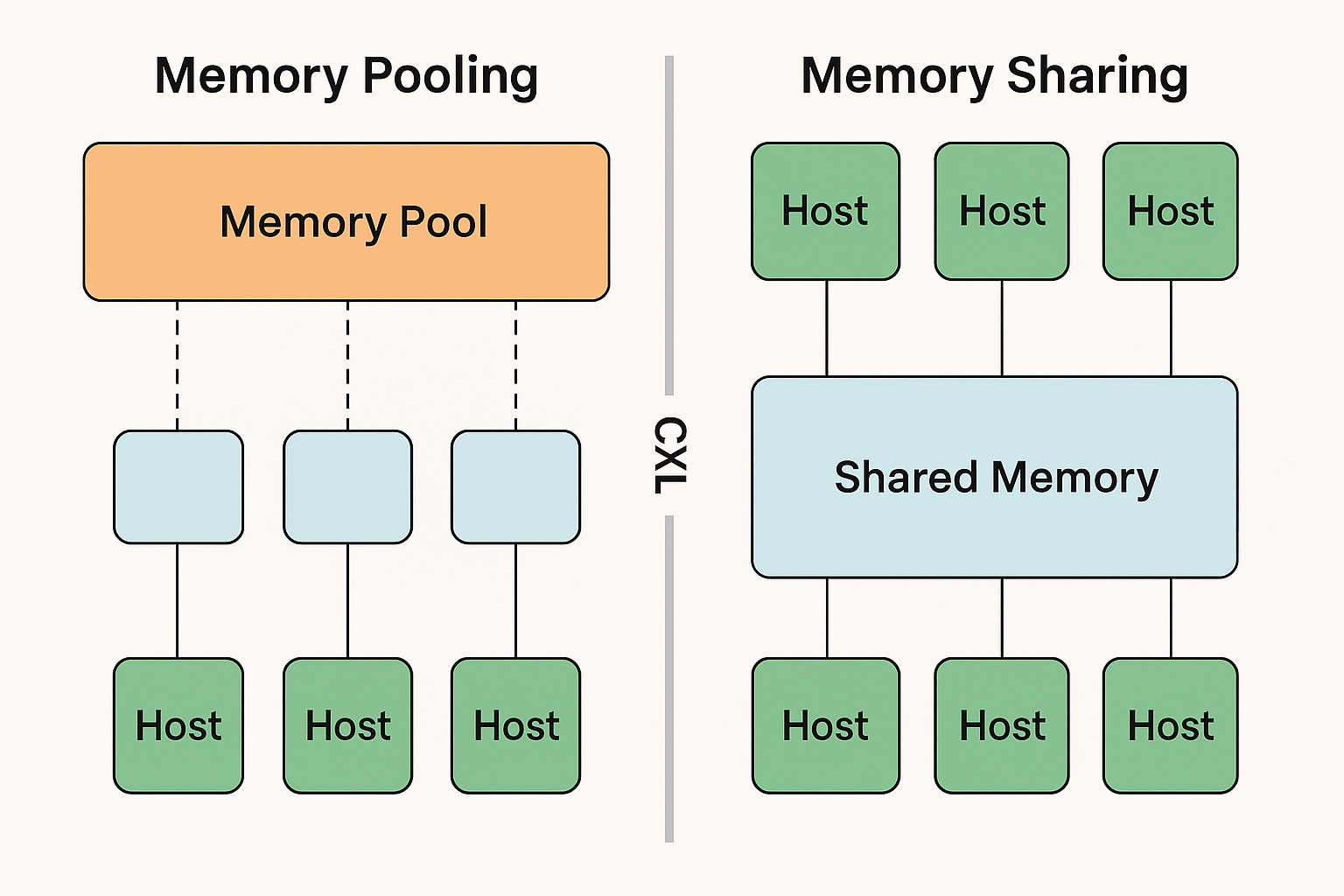
Two powerful CXL memory paradigms are pooling and sharing. Memory pooling, facilitated by CXL 2.0 and beyond with switching capabilities, allows a host to access a collective pool of memory resources. In this configuration, the memory hardware itself is shared, but each segment of memory typically belongs to a single coherency domain, ensuring isolation between hosts and providing guaranteed access for tasks like in-memory databases.
Two powerful CXL memory paradigms are pooling and sharing. Memory pooling, facilitated by CXL 2.0 and beyond with switching capabilities, allows a host to access a collective pool of memory resources. In this configuration, the memory hardware itself is shared, but each segment of memory typically belongs to a single coherency domain, ensuring isolation between hosts and providing guaranteed access for tasks like in-memory databases.
Memory Sharing takes this a step further. It enables multiple hosts to access and operate on the same memory regions concurrently. This is crucial for multi-host workloads where data needs to be processed collaboratively without the overhead of data copying.
Think of pooling as allocating distinct containers of memory to different users, while sharing is like opening up a single, shared document for multiple users to edit simultaneously. Both offer distinct advantages: pooling excels at efficient, isolated resource allocation, while sharing unlocks true collaborative processing and reduces data movement bottlenecks.
The Falcon C5022 system architecture is designed for disaggregated memory, forming the backbone of a CXL Memory Sharing solution. At its core, it comprises multiple host servers, a central CXL switch, and the Falcon C5022 chassis itself, which houses the CXL memory modules.
Each host server connects to the CXL switch via a high-speed interface, a PCIe x16 slot using a CDFP cable for connectivity. This switch acts as the central hub, managing the flow of data between the servers and the memory resources.
The Falcon C5022 chassis is purpose-built to accommodate numerous CXL memory modules, supporting up to 22 E3.S 2T CXL memory modules. These modules represent the pooled and sharable memory resources that the connected servers can access. This architecture allows for the separation of memory from the servers, creating a flexible and scalable memory infrastructure.
The Falcon C5022 delivers substantial performance and efficiency gains crucial for modern data centers. At its heart is the low-latency, high-bandwidth CXL interconnect, which facilitates near-instantaneous access to pooled memory resources. This translates to dramatically reduced data access times compared to traditional architectures, directly accelerating demanding AI and high-performance computing workloads.
By enabling dynamic memory allocation and efficient sharing across multiple hosts, the Falcon C5022 system significantly improves resource utilization. This means less idle memory and greater overall throughput from your existing infrastructure, minimizing the costly problem of stranded memory. Furthermore, the architecture supports zero-copy data sharing, eliminating the performance penalty associated with data transfers between servers, leading to more efficient processing pipelines and a lower Total Cost of Ownership (TCO).
The power of CXL Memory Sharing with Falcon C5022 unlocks transformative potential across various demanding applications:
1. What is the difference between CXL Memory Sharing and Pooling?
CXL Memory Pooling aggregates memory from one or more devices into a central shared pool, which can be dynamically allocated to different hosts as needed. CXL Memory Sharing allows multiple hosts to simultaneously access the same memory device, enabling real-time data exchange. Sharing emphasizes concurrent use of the same memory, while pooling focuses on flexible distribution of memory across systems.
2. Which applications benefit most from CXL Memory Sharing?
AI inference workloads (e.g., shared KV cache), RAG-based vector databases, real-time financial analytics, and HPC tasks all gain from reduced latency and zero-copy data sharing across compute nodes.
3. How is CXL Memory Sharing different from RDMA?
RDMA allows remote memory access but operates at the message-passing layer and typically lacks full cache coherency. In contrast, CXL Memory Sharing provides hardware-level coherency, enabling multiple processors to directly access the same memory region as if it were local, with true zero-copy semantics.
4. How can applications access shared memory?
Applications can use DAX (Direct Access), allowing them to read and write shared memory just like accessing a file, without needing major code refactoring.
5. What is the maximum capacity supported by CXL Memory Sharing?
In current industry demonstrations, CXL-based shared memory systems vary in capacity depending on hardware topology and vendor implementation. H3’s Falcon C5022 supports configuration of up to 5.5TB of memory, enabling large-scale multi-host deployments.
6. Can Memory Pooling and Sharing coexist in one system?
Yes. Many CXL-based infrastructures support hybrid deployment where both Pooling and Sharing operate concurrently within the same fabric to serve different workloads.
7. What benefits does the system gain after deployment?
After deployment, the system gains full access to coherent CXL memory, allowing hosts to use large pooled or shared memory regions and enabling applications to share data instantly. Workloads can adopt DAX for file-style access or load/store models for high-performance in-memory computing. With CXL-ready platforms such as Intel Granite Rapids and upcoming AMD CXL 3.0 servers, deployment unlocks higher memory utilization, reduced fragmentation, and support for advanced AI, cloud, and HPC applications.
In conclusion, the CXL Memory Sharing architecture, exemplified by solutions like H3 Platform's Falcon C5022, represents a paradigm shift in data center infrastructure. It directly addresses the pervasive challenge of stranded memory by enabling unprecedented flexibility, efficiency, and scalability. By transforming isolated memory silos into a dynamic, pooled resource, organizations can significantly reduce their TCO, optimize performance for demanding AI and HPC workloads, and build a truly composable infrastructure ready for future innovation. To experience this transformative potential firsthand and unlock new levels of performance and cost-efficiency for your organization, we invite you to explore our comprehensive documentation, request a personalized demo, or connect with our sales team to discuss your specific needs.