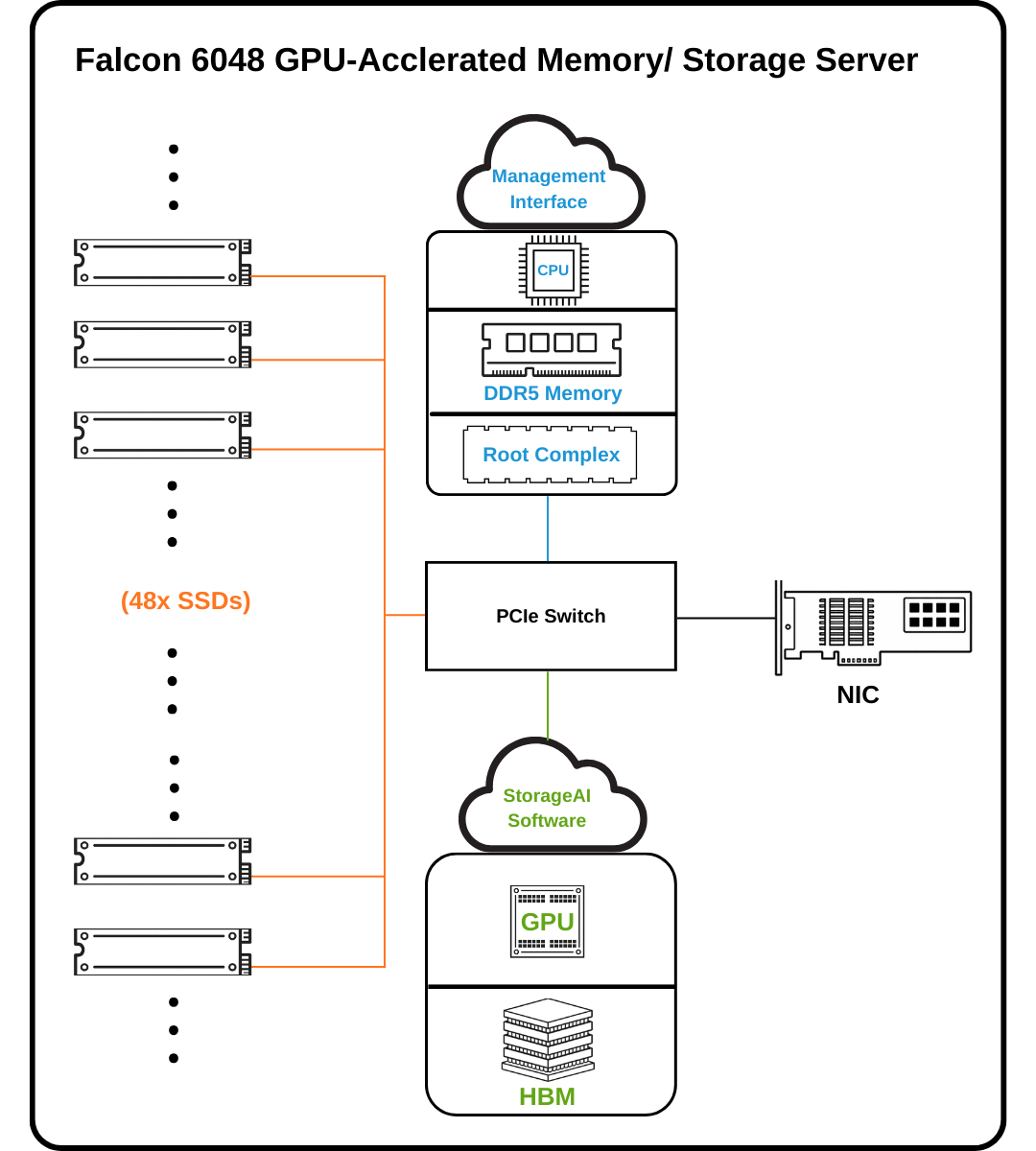
The Falcon 6048 utilizes a GPU-accelerated memory/storage architecture to expand effective GPU capacity through high-IOPS NVMe SSD integration. By orchestrating seamless data movement between GPU HBM and NVMe storage via a high-speed PCIe fabric, the system maximizes compute utilization and maintains ultra-low latency for massive-scale AI and HPC workloads.

Powered by 2 Broadcom PCIe Gen6 switches and 44 E1.S NVMe SSDs, Falcon 6048 achieves up to 200 million IOPS, delivering ultra-low latency and massive parallel throughput ideal for AI training, inference, prediction and large-scale data analytics.

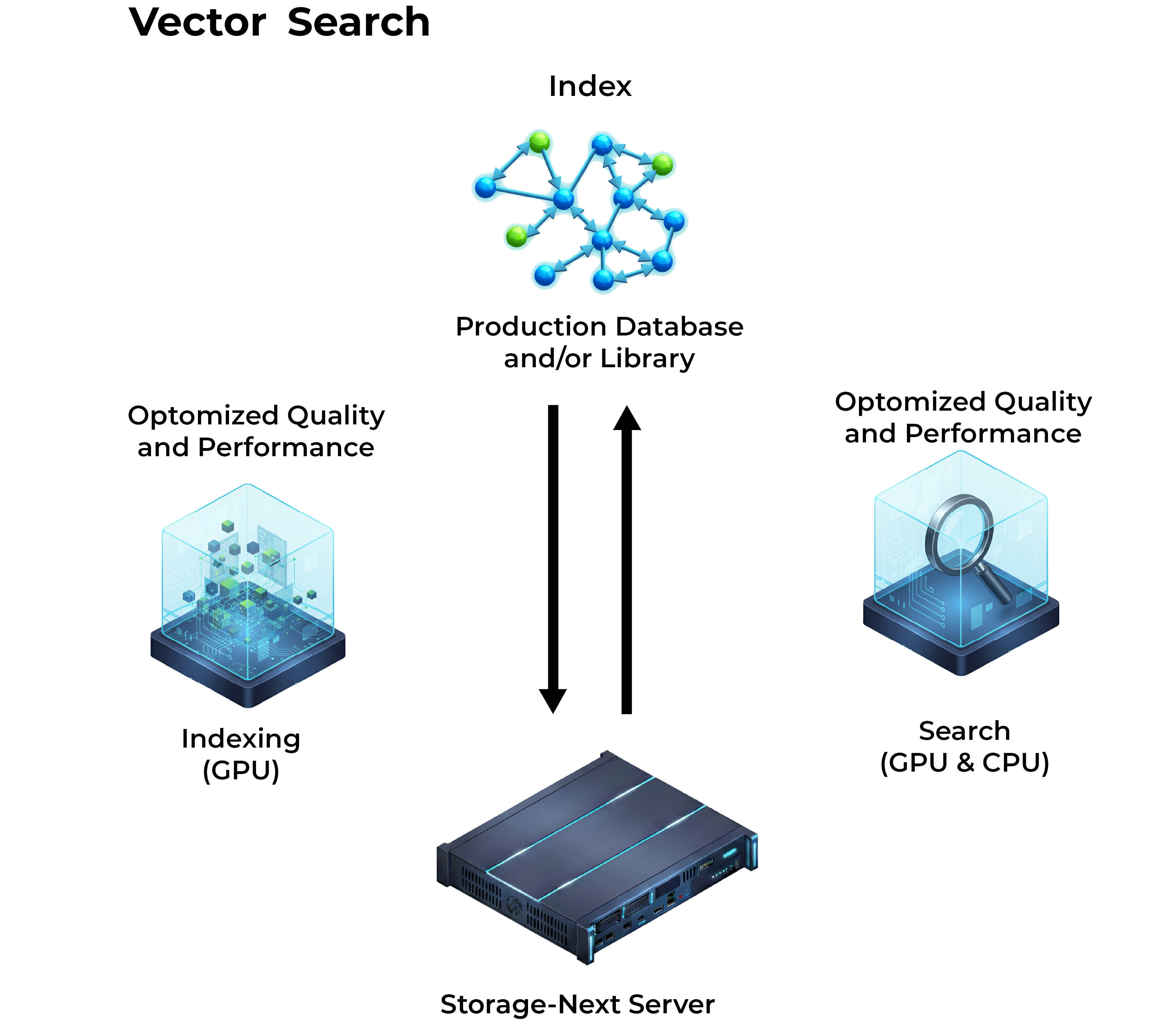
Falcon 6048 is fully optimized for GNN, delivering breakthrough performance for large-scale graph learning and analytics applications. With a GPU-centric architecture, Falcon 6048 efficiently handles the massive random I/O operations required by modern GNN workloads. By maximizing GPU utilization and minimizing dataflow bottlenecks, Falcon 6048 enables scalable, high-throughput, low-latency graph AI systems for next-gen AI.
| Management Interface | Redfish®, RESTful API, GUI and CLI |
|---|---|
| System Management |
|
| Model Name | Falcon 6048 |
|---|---|
| BMC | Aspeed AST2600 Advanced PCIe Graphics & Remote Management Processor |
| CPU |
|
| PCIe Switch | Broadcom PEX 90144 PCIe 6.0 Switch |
| Memory |
|
| NVMe SSD |
|
| PCIe Slot |
|
| Power | CRPS 185mm 3200W 80+ Titanium 2+2 |
| Fan |
Ten (10) 60x56mm fans Hot swap |
| LAN |
|
| Environmental Spec. |
|
| Dimension | 3U; 129.6 (H) x 438(W) x 850(D) mm |
| Accelerator |
|
|---|---|
| Network Cards | NVIDIA ConnectX-7, ConnectX-8, ConnectX-9 |
With the PCIe 6.0 switch at its core, Falcon 6048 delivers exceptional throughput and scalability. It supports up to 2 NVIDIA H200 GPUs, 4 NVIDIA ConnectX-9 NICs, and 48 NVMe SSDs (depending on available PCIe slots), along with 1 CPU and 8 DDR5 memory modules in the gpu-accelerated server.
This architecture is purpose-built for ultra-high IOPS performance and ultra-low-latency small-granularity data access, enabling efficient processing of massive datasets dominated by small, random I/O patterns—commonly seen in AI training, inference, real-time prediction, and data-intensive workloads.
If you want to apply for any product display, please write a form and we will contact you after receiving the message.
{kind=link}
{kind=link}