4573
Accelerate AI and HPC Applications with GeForce RTX GPUs
AI development lab implemented H3 Platform’s CDI solution to successfully leverage the computing power of multiple RTX 3090.
Read More

Power CPU based render nodes by multiple Nvidia Ampere GPUs with no pain.
We are working on an interesting project recently and we would like to share with everyone. The goal is to power our client’s render nodes with the upcoming RTX A6000 GPUs.
Our client has four 1U dual CPU servers as the render nodes, and they are planning to add eight RTX A6000s to each server with, and they also require an InfiniBand NIC for high-speed data transmission. A 1U server with maximum two PCIe slots simply could not do that, and they knew that the easiest way to overcome this obstacle is the disaggregated solution.
Image 1.
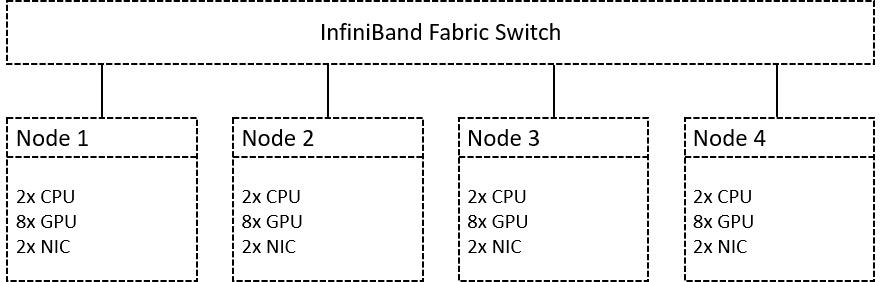
Image 1 illustrates the requirements of the planned system, each node should consist of two AMD EPYC 7742 CPUs, eight RTX A6000 GPUs, and two ConnectX 6 network interface controller.
Image 2.
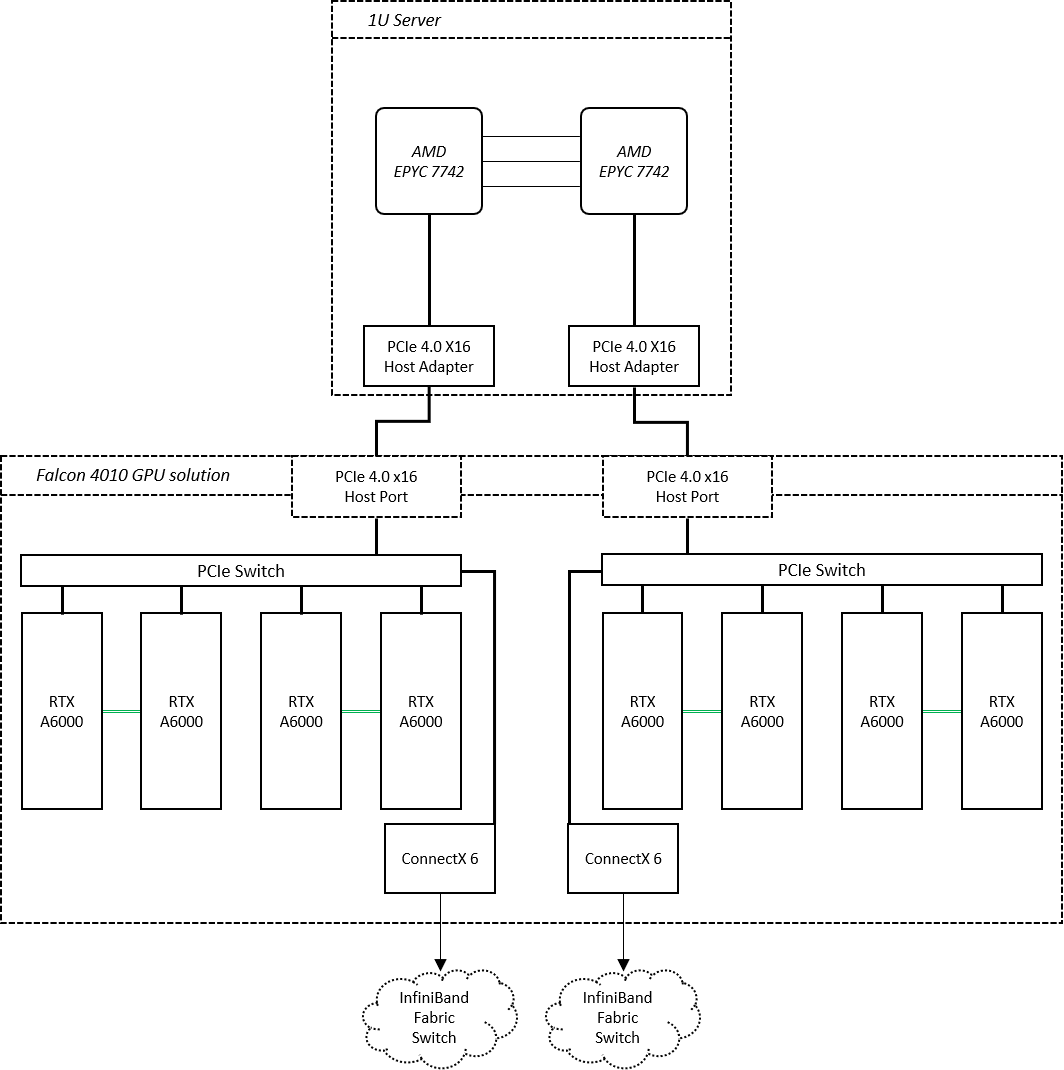
Image 2 is the composition of the nodes. By attaching a Falcon 4010 GPU chassis to the server, we create sufficient space to carry all the required devices. In addition, as the two chassis (the server and the GPU chassis) are communicating via PCIe 4.0 interface, the performance would be as good as installing the GPUs in the server itself. Moreover, the Falcon 4010 provides enough power and cooling to such high-GPU density configuration so our client can simply neglect the relevant issues while focusing on optimizing the performance. The project is on-going, and we will share more with you later. But we can see the great benefit brought by the disaggregated solution in this render farm case.
Nowadays, you can find applications of computer-generated graphics across different industries. Despite the scale, rendering high quality images requires a lot of computing resources. Taken animation as an example, from free lance film makers to big film companies like Pixar, a high-performance computing system is inevitable to the artists to visualize their great ideas, not to mention those applications that combine deep learning models and CG technologies.
Rendering high quality images (or frames) can take awfully long time, for-profit artists, studios, or companies often would leverage multiple computers, or a render farm, to speed up rendering output time. Another great benefit brought by render farm is that it helps to create a more efficient workflow by offloading compute-intensive tasks to different machines, leaving production machines on-going.
Let’s take a closer look at the computing system behind the scenes. Following images illustrate shows the basic structures of a typical render farm.
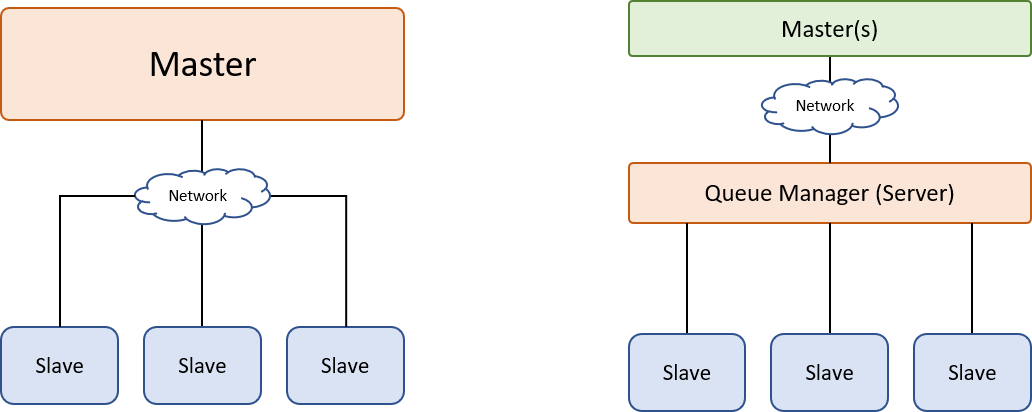
The master node is usually the one that sends out the workloads whereas the slave nodes would receive and process these workloads and send the results back to the master once they are completed. The structure in the left image is more common for free-lance creators or smaller studios. In these scenarios, the project scale is relatively smaller, therefore less render nodes and simple networking would be capable of handling the tasks. The structure in the right image demonstrates the structure of a larger scale render farm, more render nodes are required for larger scale projects, and as more workloads are offloaded to the slave machines, a queue manager is needed to distribute the tasks among slave nodes for optimal rendering schedule.
The above image illustrates the composition of a slave nodes. A single render node is an independent computer with all necessary components such as a CPU, RAM, and operating system. And like the production machine, a copy of production software (i.e., render engine) should be installed to the node so that it can perform the render tasks. A render farm would combine multiple nodes to process frames in parallel.
Multiple nodes working in parallel.

GPUs are extremely efficient in parallel processing. Given thousands of cores, the parallel processing architecture brings great benefit to rendering as the fundamental goal is to calculate and present images. More and more rendering engines now support GPU hardware acceleration, therefore, to further speed up image processing time, people introduced GPUs into rendering to increase the performance and efficiency.
Nonetheless, introducing GPU not only cost a lot of money, but also makes the hardware configuration more complicated. As GPUs are power-hungry and comes in various form factors, building a GPU powered system requires more effort and computer knowledge. Especially when you want to leverage the performance of multiple GPU in a node, power and cooling solution will be a great challenge. Moreover, if you have an existing CPU based render farm, the chassis of your current nodes may not easily fit GPUs, creating barriers to switch over to more powerful GPU nodes.
Recalling the case that we discussed in the beginning of this post, our clients could have implemented GPU servers that meet their requirements, and that is what most people would do. But there are several downsides of switching over to GPU servers, first being that they would have to eliminate the old 1U servers, which is kind of a waste because they are still in good shapes, second is that the resources are packed together in a server chassis, making it difficult to adjust the performance precisely.
Dedicated GPU server as a render node.
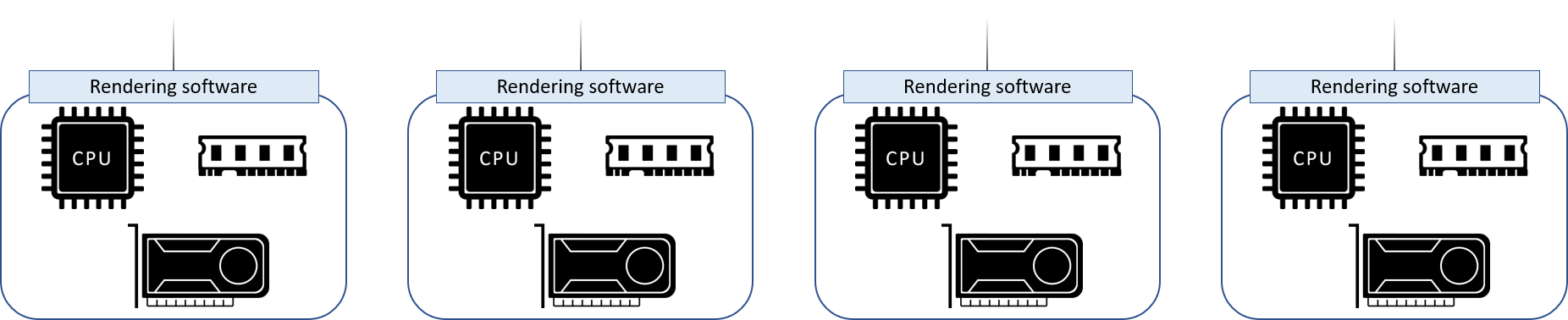
In contrast, a disaggregated solution would give more flexibility. When scaling out the system, users can treat CPUs and GPUs separately, or reconfigure the nodes with existing resources with much less effort. After all, buying either a CPU server or a couple GPUs when upgrading the system would be much cheaper than buying entire GPU server.
Disaggregate GPU from CPU servers.
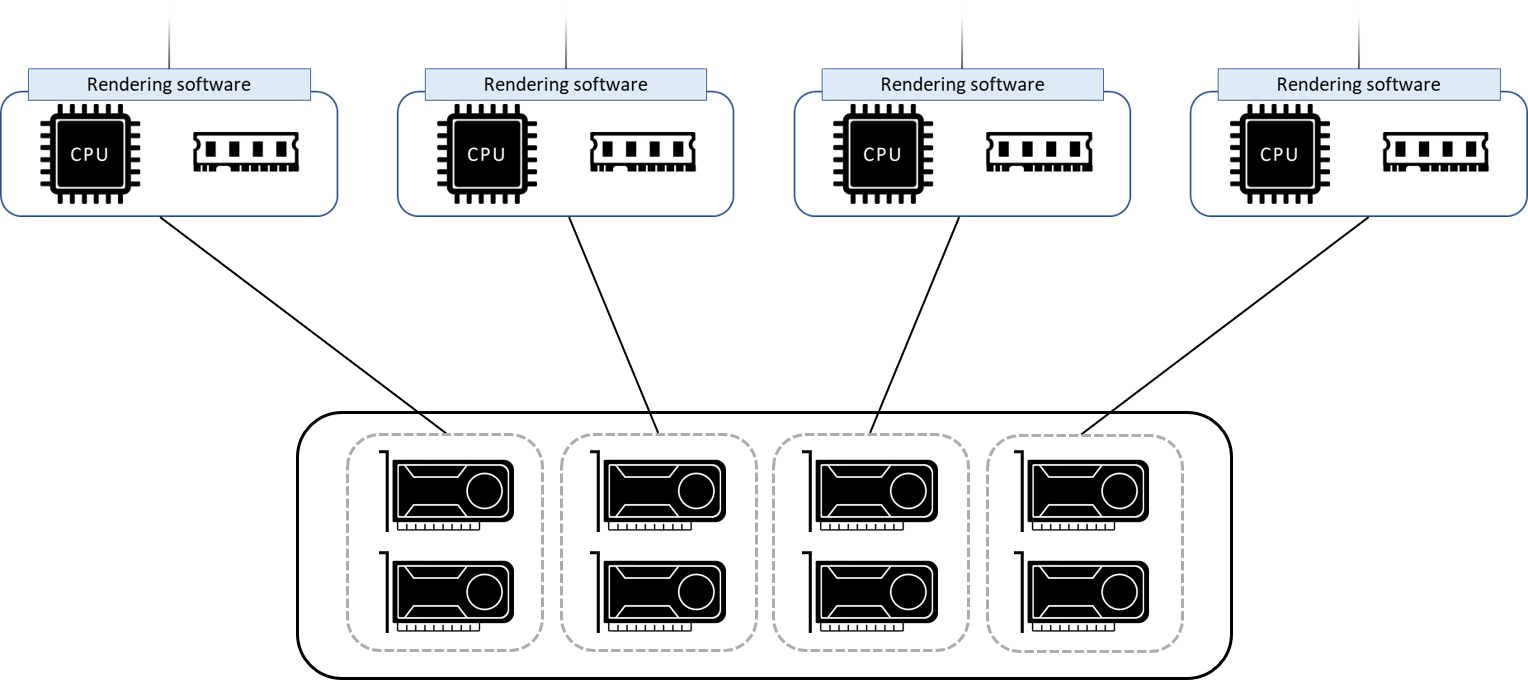
Also, we can add as many GPUs as we want to the node (if the CPU is powerful enough to drive them). And because the server chassis only deal with CPUs and RAM, it significantly lowers the requirements when sourcing servers.
Although we mainly discuss render farm in this post, the disaggregated architecture can actually be applied to any other GPU accelerated systems. This approach assures high-density, scalability and flexibility. On top of that, if the solution is PCIe based (or any high-speed interface), you would not have to sacrifice any performance for all the merits mentioned above.