Knowledge Base

Traditional IT infrastructure architecture where all CPUs, memory, storages, and accelerator devices are put together in a single chassis as a standalone computing system, is known to have several downsides, including hardware inflexibility and low scalability. Thus, causing significant over provisioning of IT resources. IT experts have been working hard to solve this issue by introducing different hardware architectures for better IT efficiency.
Converged and hyperconverged architectures are being widely adopted in datacenters to disaggregate compute, storage, and networking for higher flexibility and scalability of the systems. With the help of virtualization, the efficiency of IT resources becomes way better than that of the traditional architectures.
Nonetheless, the converged and hyperconverged infrastructure relies heavily on networking switches. When scaling up the systems, IT consumers often have to purchase extra network switches and JBODs, sometimes even extra compute nodes that are not really necessary. For some vender-locked hyperconverged system, the scaling may require the purchase of entire rack of hardware. Even with all the hard work done by IT experts, the device idle rate in datacenter is still not that idle in modern datacenters. In fact, the article Stop Overprovisioning. Learn about effective 4 ways to optimize your cloud resources mentioned that the Flexera State of the Cloud Report in 2020 indicates that the waste of spending in datacenters due to overprovisioning is almost 40%.
Another key factor concerning this issue is the increasing need of accelerator devices in the datacenter. Whether converged or hyperconverged focuses more on the storage. This would not be a problem in the past years as the number of accelerators are not that significant to CPUs or storages, but as the usage of accelerator devices increases, the utilization rate of accelerators must be taken into consideration just like the storage devices. This exposes another downside of converged and hyperconverged systems. The accelerator devices would experience high idle rate if installed in the compute nodes, on the other hand, if we were to disaggregate accelerators from compute node, the performance of would be impacted by the network fabrics. That is something we don’t want to see especially when the price tags of these accelerators are high.
H3 Platform is addressing the issue of low efficiency in datacenters with a different approach, that is to disaggregate compute nodes, storage, and accelerators with PCIe fabric based composable solution. With the ability to cascade PCIe fabric switches, it is possible to scale any compute system both vertically and horizontally.
H3 Platform has successfully cascaded multiple PCIe fabric switches in two modes, without noticeable impact on device performance, with the emphasis on the peer-to-peer (p2p) communication between accelerators.
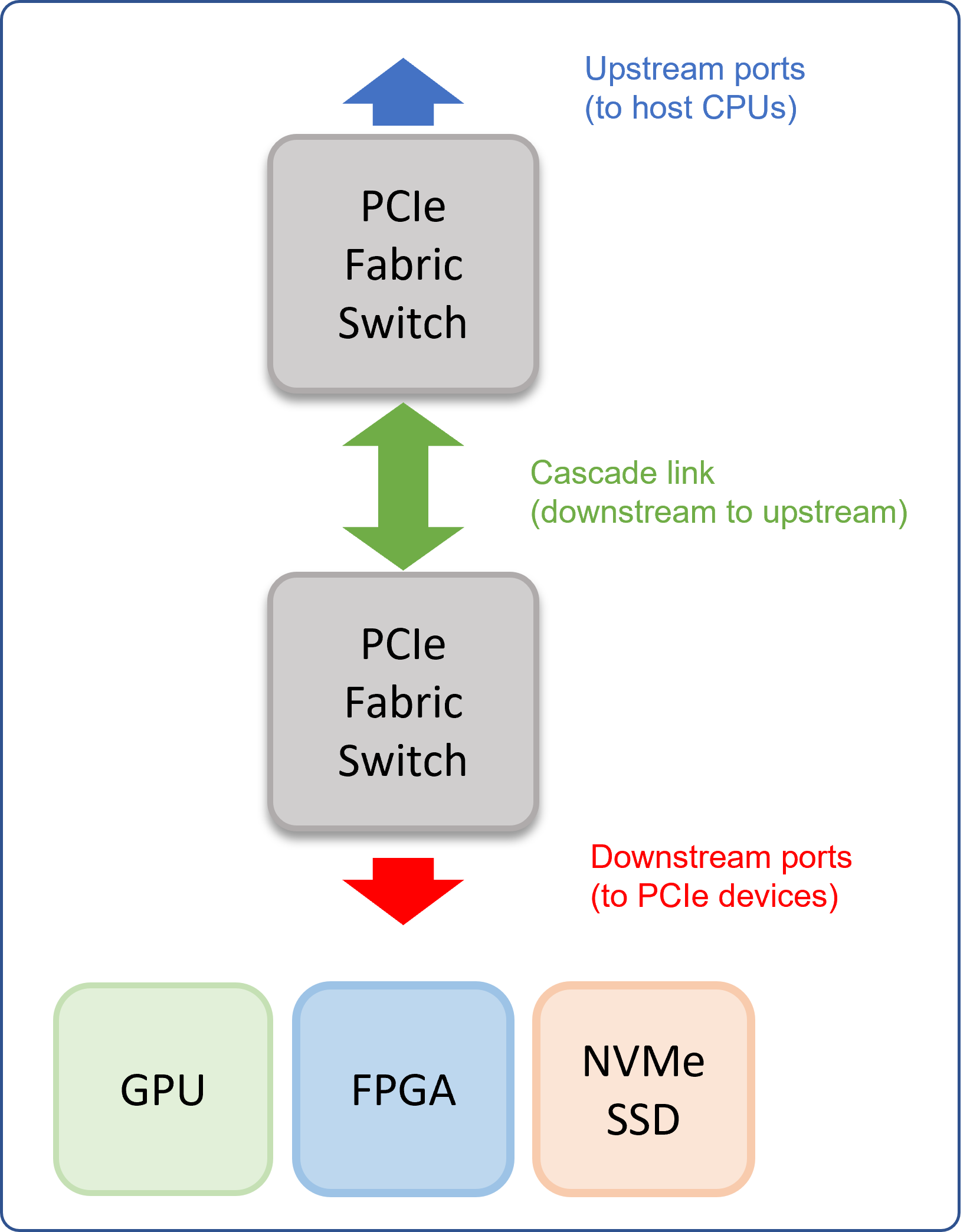
Vertically cascade:
Increasing the depth of the system architecture by adding PCIe switches layer after layer in the system.
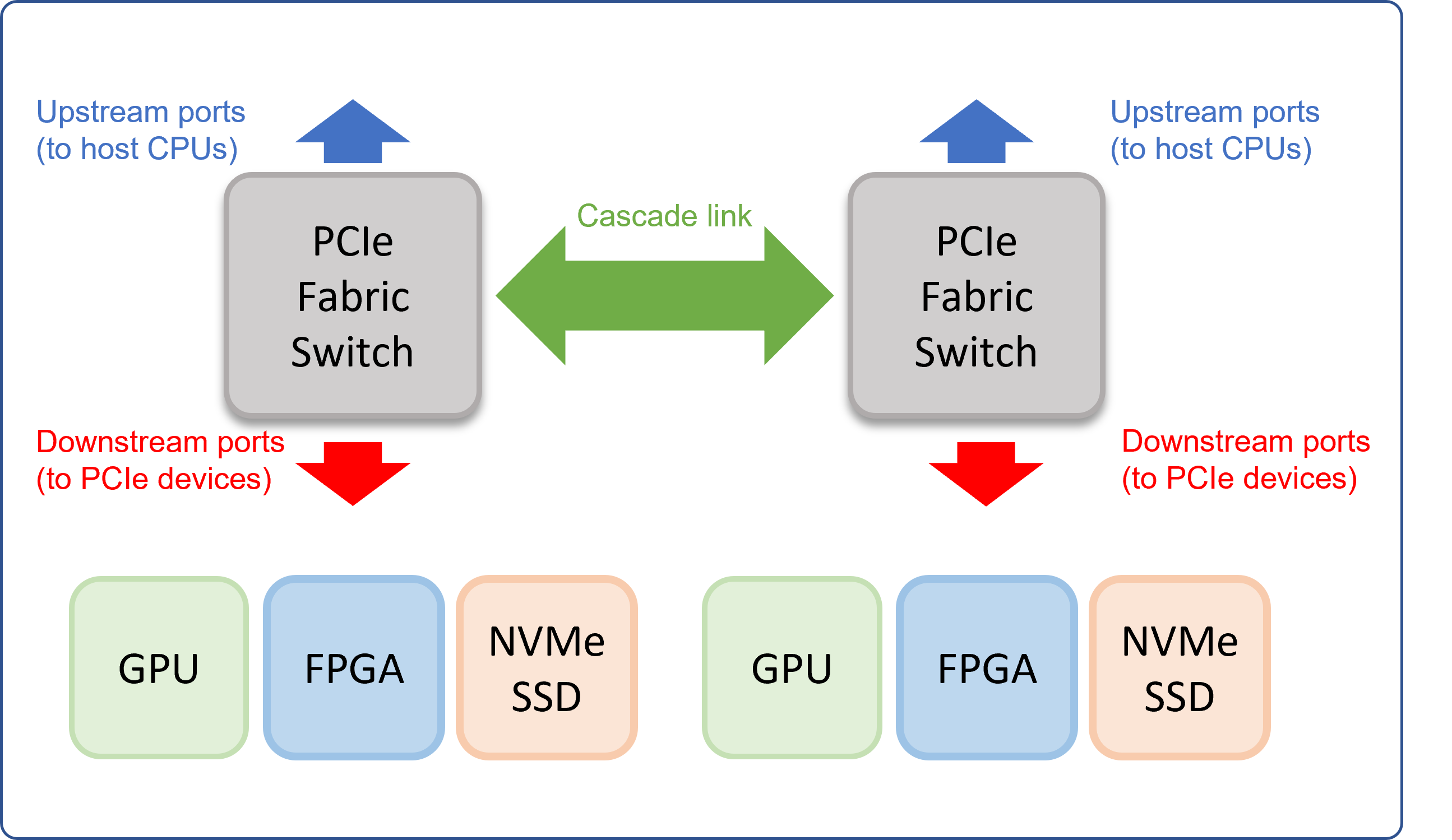
Horizontally cascade:
Daisy chain PCIe fabric switches for larger pool of resources. Ideal for applications that relies heavily on P2P of large number of accelerators for parallel computing.
This cascade capability will be integrated into the Falcon Composable Solution soon, giving even more flexibility and scalability for your system design. With the H3 device management software, now it is possible to add a pool of resource anywhere in the system while still being able to allocate the resource to any computing node.
As we have discussed many times, Falcon PCIe expansion chassis are PCIe fabric switches integrated. For users who’d like to build a smaller scale composable infrastructure, the network fabric can be taken out from the system, simply leverage PCIe as external interconnect between computing node and the resource pool. On the other hand, large-scale composable infrastructure can take advantage of the integrated PCIe fabric to reduce the number of network fabrics required in the entire system. Either way the Falcon composable solution assures performance and significantly reduces the spending on hardware while the composability enables dynamic allocation of resources and higher device utilization rate further reduces the IT footprint in the datacenters.
In addition to the aforementioned benefits, the Falcon PCIe expansion chassis are plugged and play, it speeds up deployment process. To implement Falcon Composable Solution, IT managers only have to connect the expansion chassis directly to any compute node with the external PCIe cables then it’s good to go. Following the implementation of Falcon composable solution, the system management would be much easier as well. Now you have only one protocol, which is PCIe, between resource pools and a unified management interface.
We are currently at the era of PCIe4.0, and PCIe 5.0 will soon, perhaps at the end of 2023, take over datacenters as the primary protocol for device communication. In order to successfully disaggregate computing resources for higher utilization rate, the composable architecture based on PCIe fabric switches perhaps is the most direct and economically efficient solution for datacenters.