Knowledge Base

H3's
integration of the Broadcom PCIe Gen5 89144 switch chip marks a pivotal moment
in PCIe Gen5 GPU expansion. Utilizing Fabric Peer-to-Peer (P2P) technology, we
achieve significantly enhanced performance.

Figure1. System Topology of L40S GPU Fabric P2P
Direct P2P communication between NVIDIA CUDA GPUs relies on the PCIe bus. Without PCIe support, data transfer involves traversing host memory, introducing latency and CPU intervention. PCIe Fabric P2P support enables direct GPU-to-GPU data sharing and streamlining processes, which is beneficial for applications requiring frequent data exchange between GPUs. However, it depends on PCIe bus support.
The PCIe bus is a standardized interface for high-speed data transfer between hardware devices in a computer system. CUDA GPUs leverage PCIe for P2P communication, facilitating direct data exchange without using host memory. Fabric P2P communication allows CUDA GPUs to share data directly, which is crucial for parallel and high-performance computing, reducing data transfer latency and enhancing efficiency.

Figure2. Diagram of Data Transferring through the CPUs (example: GPU0 to GPU2)
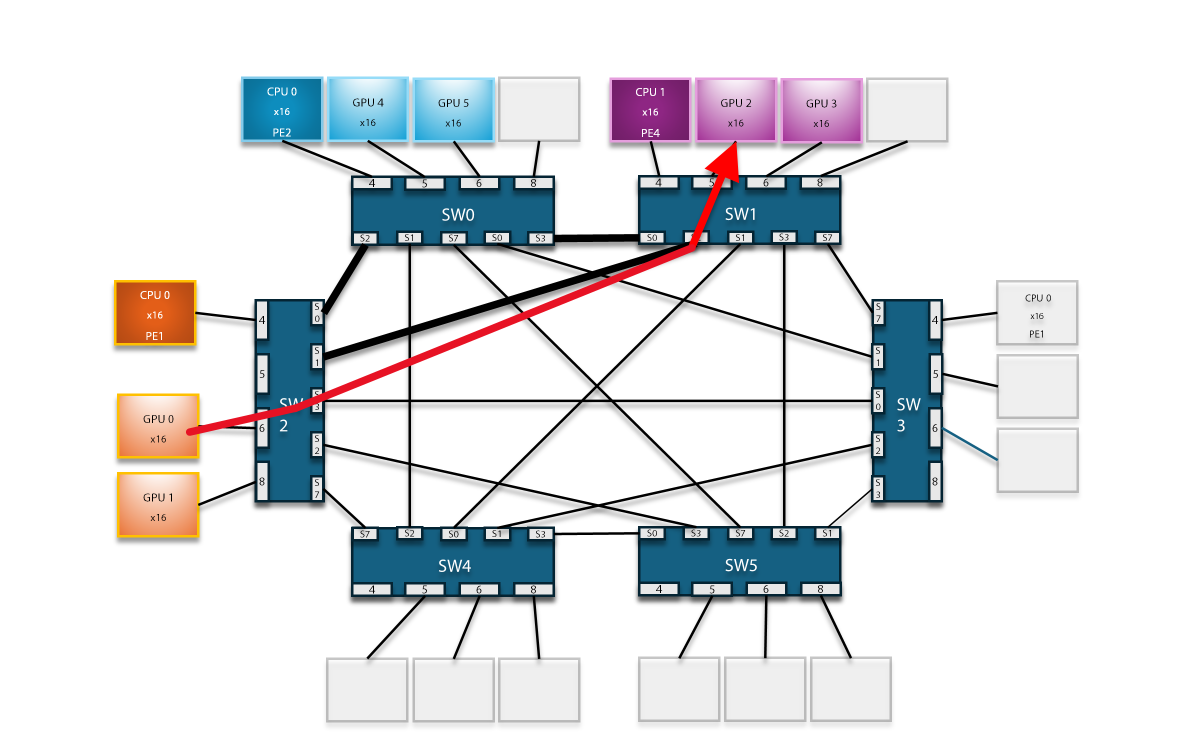
Figure3. Diagram of Data Transferring Notthrough the CPUs (example: GPU0 to GPU2)
In
actual test data, the difference is evident: when Fabric P2P is not enabled,
data is transmitted through the CPU (QPI / UPI path), resulting in a
unidirectional P2P bandwidth of only 20.7GB/s. It is supposed to be even lower,
around 10 GB/s, since there could be other data transferring operations in the
QPI/UPI path. However, with Fabric P2P enabled, the data do not go through the
CPU (QPI / UPI) and directly takes the switch fabric path for P2P, achieving a
unidirectional P2P bandwidth of 25.6GB/s, which reveals a significant
performance improvement around 23.7% higher bandwidth. For bidirectional P2P
bandwidth, without Fabric P2P enabled, the bandwidth through CPU is around
15.5~29.9 GB/s, but the P2P facilitated performance can be up to 49.4 GB/s, almost
doubled! There is no need to mention latency with significantly lowered µs as
90%.

Table. Benchmark Test: P2P Data Transfer through CPUs vs. Not Through CPUs
What Does It Imply?
AI
workloads, encompassing machine learning and deep learning, necessitate a
state-of-the-art computing architecture enabled by PCIe Gen5. This necessity
arises from the substantial generation, movement, and real-time data processing
inherited in AI applications. For instance, a smart car generates about 4 TB of
data/day, and the sizes of AI/ML training models double approximately every 3-4
months.
Across
various industries, AI applications demand significant memory bandwidth to
handle extensive datasets effectively. As a crucial role, GPUs support parallel
computing, low-precision computing, and empirical analysis. Therefore, AI/ML
workloads require robust computational power, with GPUs emerging as the ideal
solution to meet these demands.
With
an aggregate link bandwidth of 128 GB/s in an x16 configuration, PCIe Gen5
efficiently addresses the bandwidth-intensive needs of AI/ML applications. H3's
GPU Expansion Solution utilizes PCIe Gen5 as a standardized interface for
high-speed data transfer, enabling them to handle massive datasets even more
efficiently. The Fabric P2P realization among GPUs magnifies the application
values with heightened performance.
Looking
beyond AI/ML applications, the traditional data center paradigm is transforming
due to the widespread shift toward cloud computing. Enterprise workloads are
increasingly moving to the cloud, with over 60% being cloud-based in 2019. Data
centers are embracing hyperscale computing and networking to cater to the
demands of cloud-based workloads. The economies of scale, fueled by the
continuous increase in bandwidth per physical unit of space, are expediting the
adoption of higher-speed networking protocols, doubling in speed approximately
every two years: 100GbE -> 200GbE -> 400GbE -> 800GbE. PCIe Gen5
effectively meets these requirements by supporting higher speed networking
protocols and facilitating faster interconnects between system devices.
In
addition to its groundbreaking features, H3's GPU Expansion Solution extends
its capabilities to enable Fabric P2P even across switches. This advancement
signifies H3's achievement, allowing seamless Peer-to-Peer communication
between GPUs in a scaled cascaded downstream device pool. The ability to
transcend switch boundaries enhances the flexibility and scalability of the
solution, catering to diverse and expansive computing environments.
Discover
the unparalleled potential of H3's GPU Expansion Solution with Fabric P2P
technology. Elevate your computing experience, enhance performance, and embrace
the future of high-speed data transfer. Contact us today to explore how our
innovative solution can revolutionize your GPU expansion needs.