7055
On Premise Render Farm Transformation
Discuss how disaggregated architecture can simplify the process to adopt GPUs to improve performance of traditional CPU based render farm.
Read More

We’ve selected four of the most highly discussed NVIDIA GPUs in professional fields for this comparison: RTX 5090, RTX PRO 6000 Blackwell, RTX 4090, and RTX A6000 Ada. Among them, the RTX 3090 and RTX A6000 represent the previous generation built on the Ampere architecture, while the RTX 4090 and RTX 6000 Ada continue the legacy of the Ada Lovelace architecture. The latest entries, RTX 5090 and RTX PRO 6000, are powered by NVIDIA’s newest Blackwell architecture.
Through this comparison, we aim to help users understand which GPU is best suited to various application scenarios. Please note: all test results in this article are based on a single GPU, with no multi-GPU or cluster configurations involved.
Please be noted: Specifications and performance figures for RTX 5090 and RTX PRO 6000 Blackwell are based on current leaks, rumors, and projected benchmarks. Final specs may vary upon official release

GPU Specification Comparison Table
Why Are the CUDA Cores in the RTX 5090 So Important? — The Foundation of GPU Performance
Blackwell Architecture: A New Peak in Performance
Both the RTX
5090 and RTX PRO 6000 Blackwell adopt NVIDIA’s latest Blackwell architecture,
built using TSMC’s 4nm process. While this is the same node as Ada Lovelace,
Blackwell offers significant improvements in architectural design and core
count.
The
Blackwell GPUs drastically increase the number of CUDA cores and integrate
fifth-generation Tensor Cores and fourth-generation RT Cores, resulting in a
generational leap in performance for AI acceleration and ray tracing. CUDA
cores are the fundamental units for parallel computation in GPUs. An increase
in their number means the GPU can handle more concurrent tasks, which is
critical for demanding workloads like AI model training, 3D rendering, and
scientific simulations.
Which GPU is Better for Deep Learning: RTX Pro 6000 Blackwell vs RTX 5090?
In terms of
deep learning, both the RTX Pro 6000 Blackwell and RTX 5090 are based on
NVIDIA's latest Blackwell architecture, and they each target different segments
of the AI development landscape. The RTX Pro 6000 Blackwell is equipped with a
massive 96GB of GDDR7 memory and ECC support, making it highly suitable for
training large-scale language models and running long-duration inference jobs.
On the other hand, the RTX 5090, while also powerful, is more
consumer-oriented, offering around 32GB of GDDR7 and no ECC, which may limit
its usage in mission-critical applications.
Based on early leaked benchmarks and projects, the RTX 5090 is expected to deliver impressive raw performance, the RTX 5090 delivers impressive raw performance, even
surpassing the RTX 4090 in many inference workloads. Its compute power makes it
a great choice for developers who want high speed at a much more accessible
price point. However, the RTX Pro 6000 is built for professional environments,
offering not just more memory but also greater stability, ECC reliability, and
certification for workstation use.
Another
major consideration is cost. The RTX Pro 6000 Blackwell is expected to be
priced above $11,000, which is more than five times the projected price of the
RTX 5090. That price difference may only be justifiable for users who require
the extended memory capacity and ECC capabilities for enterprise-scale training
or multi-modal AI workloads.
Ultimately, both GPUs are extremely capable for deep learning. The right choice comes down to your specific workload: whether you prioritize raw power and value (RTX 5090), or memory capacity and reliability (RTX Pro 6000 Blackwell). As of now, many details about the RTX 5090 and RTX PRO 6000 remain unconfirmed by NVIDIA. Readers should treat the information as speculative until official sources are available.
RTX Pro 6000 vs RTX 5090 vs RTX 4090: Professional Workloads and Real-World Benchmarks
Let us take a look
at how the latest GPUs from NVIDIA perform under professional workloads. All
three cards—RTX Pro 6000, RTX 5090, and RTX 4090—support hardware-accelerated
ray tracing and are built on high-performance silicon. However, the difference
lies in their architecture, power headroom, and rendering efficiency.
Both the RTX
Pro 6000 and RTX 5090 are based on the new Blackwell architecture, featuring
fourth-generation RT cores with full support for advanced techniques like
Opacity Micro Maps (OMM) and Displaced Micro-Mesh (DMM). These improvements
help reduce memory usage and dramatically accelerate real-time path tracing.
Meanwhile, the RTX 4090, while still powerful, is based on the previous Ada
Lovelace architecture and lacks some of the low-level optimization present in
Blackwell chips.
Preliminary 3DMark Speedway results shared by early testers suggest a performance gap. At full power (556W),
the RTX Pro 6000 reaches 157.4 FPS, leading the pack. The RTX 5090 follows with
146.1 FPS at 551W, while the RTX 4090 trails behind at just 101.2 FPS on 408W.
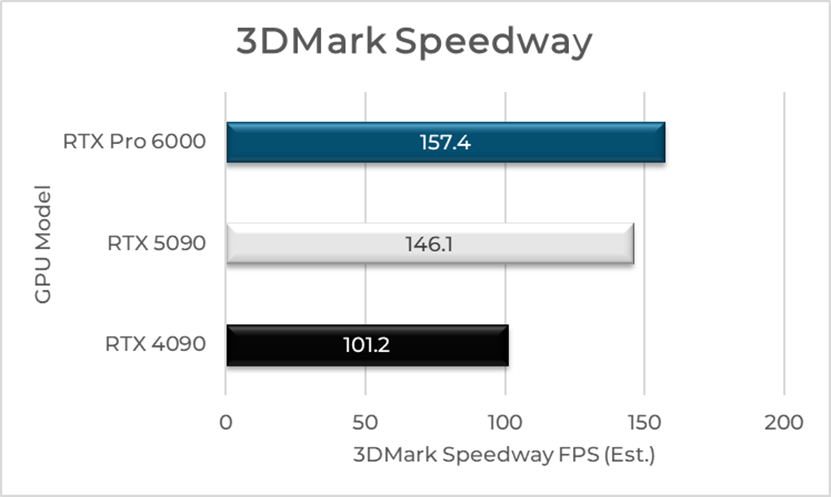
Bar Chart of Power Efficiency – 3DMark (FPS/Watt)(Source: der8auer, "Screw your RTX 5090 – This $10,000 Card Is the New Gaming King", YouTube, June 2025)
These
differences may seem incremental between the top two cards, but they become
significant in rendering pipelines where every second of compute time matters.
The Pro 6000 also demonstrates better scaling under reduced power targets,
offering 146.5 FPS at 75% power (449W), and still surpassing the 4090 even when
capped at just 300W.
We can say
that the RTX 4090 is now clearly a generation behind, and while it remains a
popular choice for creators and developers, both Blackwell GPUs outperform it
by a wide margin. The Pro 6000 pushes performance even further, particularly in
environments that benefit from ECC memory, high VRAM, and workstation-class
thermal tolerance.
RTX Pro 6000 vs RTX 5090 vs RTX 4090: Gaming Performance Compared
A new benchmark test using Cyberpunk 2077 at
4K Max settings (no Ray Tracing, no Path Tracing) reveals even more about the
gaming potential of these GPUs. The test system was built on an ASUS Crosshair
X870E Hero motherboard with a Ryzen 9950X3D processor and 32GB of DDR5-6000
memory on Windows 11 24H2.
In this
setup:
RTX Pro 6000 achieved an average of 120 FPS, with a 1% low of 81 FPS, and
consumed 596W. RTX 5090 delivered 105 FPS on average, with a 1% low of 72 FPS,
drawing 518W. RTX 4090 managed 72 FPS average, 1% low of 57 FPS, at 379W power
consumption.
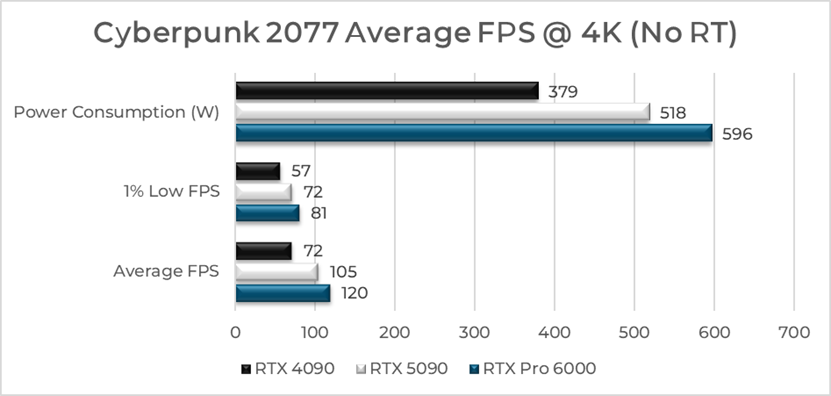
Bar Chart of Cyberpunk 2077 Average FPS @
4K (No RT)(Source: der8auer, "Screw your RTX 5090 – This $10,000 Card Is the New Gaming King", YouTube, June 2025)
These
results highlight the raw gaming performance advantage of the RTX Pro 6000,
especially in heavy workloads like Cyberpunk 2077. While its power consumption
is high, it leads across all performance metrics. The RTX 5090 balances strong
performance with slightly better efficiency. Meanwhile, the RTX 4090 lags
behind both newer Blackwell cards, showing its generational gap.
Benchmark
results retrieved from independent reviewers such as Der8auer and sourced from
Star Wars Outlaws (4K Max) and 3DMark test data (der8auer, 2025).
The charts
clearly show that the new Blackwell architecture delivers a noticeable
improvement in gaming workloads. In titles like Star Wars Outlaws, the RTX Pro
6000 achieves up to 99 FPS, outpacing both the RTX 5090 at 89 FPS and the
previous-gen RTX 4090 at 70 FPS.
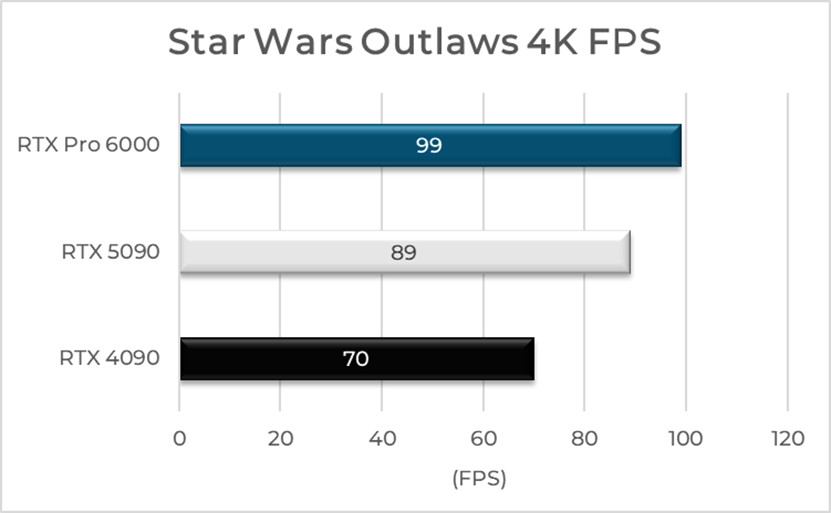
Bar Chart of Star Wars Outlaws 4K FPS (Source: der8auer, "Screw your RTX 5090 – This $10,000 Card Is the New Gaming King", YouTube, June 2025)
Likewise, in
synthetic benchmarks like 3DMark Speedway, the Pro 6000 leads again, pushing up
to 157.4 FPS, followed closely by the RTX 5090 at 146.1 FPS, and the 4090
significantly lower at 101.2 FPS.
Despite
being marketed as a professional GPU, the RTX Pro 6000 surprisingly excels in
gaming performance. However, its 600W+ power consumption and server-class
thermal profile make it impractical for most gamers. The card is large, hot,
and expensive—coming in at around $11,000. While it delivers extreme
performance, it’s clearly overkill for gaming.
On the other
hand, the RTX 5090 offers a far more balanced solution. It nearly matches the
Pro 6000 in gaming frame rates while drawing slightly less power (~550W). Most
importantly, it’s priced at a much more accessible $1,999, making it the likely
go-to option for gamers who want top-tier performance without entering the
workstation GPU territory.
As expected, the RTX 4090 still holds strong in the consumer gaming segment but is now visibly outclassed by its newer Blackwell counterparts. With just 24GB of GDDR6X and a power draw of 450W, it's more efficient but not competitive with the latest flagship cards in raw FPS.
Disclaimer: This article includes speculative content based on pre-release information and projected benchmarks. Actual performance and specifications may differ once the products are officially launched
Reference:
der8auer. (2025, June 1st). Screw your RTX 5090 – This $10,000 Card Is the New Gaming King [Video]. YouTube. https://www.youtube.com/watch?v=o21CDqlCSpsWilliams, W. (2024, March 14). Details of Nvidia’s fastest video card ever leak: RTX Pro 6000 Blackwell GPU will have 96GB GDDR7 ECC memory. TechRadar. https://www.techradar.com/pro/details-of-nvidias-fastest-video-card-ever-leak-rtx-pro-6000-blackwell-gpu-will-have-96gb-gddr7-ecc-memory