Since late 2023, generative AI models like ChatGPT have excelled across
various fields. In 2024, we expect a surge in applications based on Large
Language Models (LLMs), speeding up content creation in text, videos, images,
and audio, even in unconventional areas. For the recent update as the example,
StarCoder2 is coming out to generate code, and Now Assist for
Telecommunications Service Management (TSM) by NVIDIA AI may powerfully enhance
customer service in telecom companies. As firms seek cost savings and adopt AI,
its widespread use will drive societal innovation. The evolution from hardware
to applications will continue to be driven by Large Language Models, affecting
AI chip production, accelerators, memory tech, and upper-layer applications.
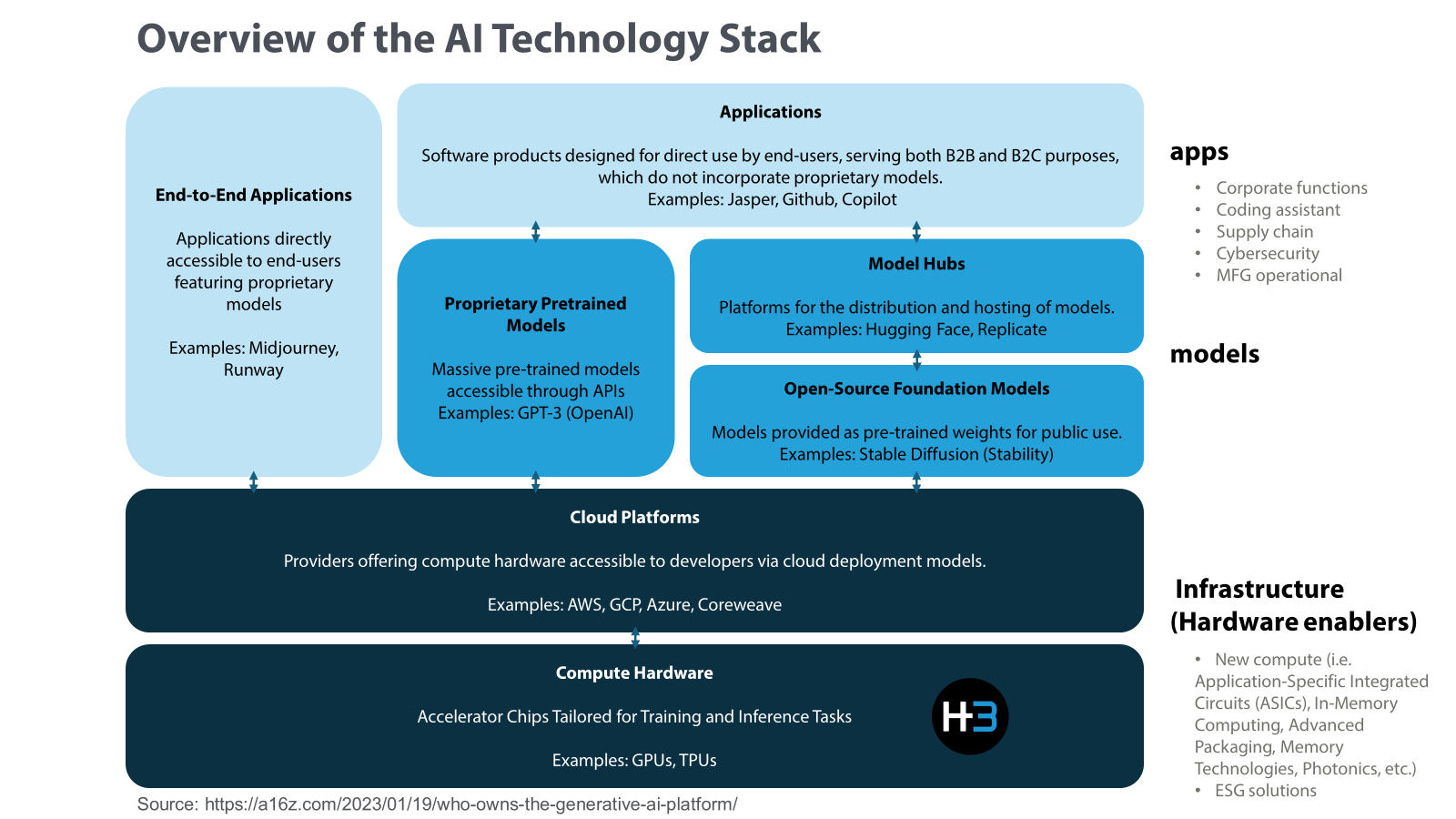
Figure 1: Overview of the AI Technology Stack
What can H3 bring about
What can H3 bring about in this technical revolution? As depicted in Figure 1,
the AI tech ecosystem encompasses various partners within the industry. H3's
contribution with GPU solution and memory pooling falls under the Compute Hardware
layer, supporting the development of models built upon which as integral
components. These infrastructure optimizations facilitate the development and
deployment of applications, ultimately contributing to the transformative
impact of AI on modern society.
In the processes of model training and data inference, which are
fundamental to AI, GPU acceleration plays a crucial role. H3's PCIe Gen5
composable GPU solution stands out by accommodating up to 10 GPU modules within
a single chassis and facilitating direct GPU-to-GPU communication, bypassing
the need for CPU intervention. This innovative composable architecture
maximizes the potential of GPU acceleration.
Addressing Memory Challenges in AI Infrastructure
On the other hand, as the AI trend overturns the world, another problem
to face is the obsolete system architecture. As the flushing in of data and
application processing workload, the requirement of memory will surge,
resulting in the running out of memory or spilling into the disk, which will
seriously degrade performances due to low bandwidth and high latency.
Figure 2. Infrastructures Driven by LLM
Applications (Source: Applied Materials)
CXL memory technologies can be the way out of the new situational
difficulties. As a solution, CXL memory tech makes up the gap between
direct-attached memory and SSD to unlock the power of AI microprocessors in AI
infrastructure. In the CXL memory pooling solution, CXL memory expanders are
installed in the JBOM (Just-a-Bunch-of-Memory) as a pool, with the switch to
create memory fabrics to enlarge memory capacities for the CPU. Having access
to memory with low latency and high bandwidth, CPUs can eliminate the
out-of-memory and spilling-to-disk issues running AI and Machine Learning
applications. It is Memory Technology depicted in Figure 2, with H3 within it, that is capable of contributing to this trend.
Learn more about CXL Memory Pooling
As generative AI models continue to advance, we expect to see a
significant increase in the use of Large Language Models (LLMs) across various
domains. This rise in LLM-based applications highlights the growing impact of
AI on diverse sectors. As more and more firms adopt AI to drive cost savings
and innovation, the transition from hardware to applications is being propelled
by Large Language Models.
H3 can help in the ongoing technical revolution as it
provides infrastructure optimizations within the Compute Hardware layer. It
offers a GPU solution and memory pooling capabilities that support the
development and deployment of AI applications while enhancing their efficiency
and performance. Additionally, H3's PCIe Gen5 composable GPU solution maximizes
the power of GPU acceleration, and CXL memory technologies address the growing
demand for memory in AI infrastructure. By enabling access to low-latency and
high-bandwidth memory, H3 helps overcome memory constraints, which ultimately
drives the transformative impact of AI on modern society.