With the
development nearing its limits, where enhancing computer performance by adding
more transistors on a single processor to increase speed and complexity becomes
challenging, the traditional vertical scaling model is no longer viable.
Instead, horizontal scaling has become the predominant approach in system
architecture. In the past, due to the high remote communication costs
associated with the distributed shared memory model, horizontal scaling has
consistently adopted the traditional message-passing model. However, with the
advent of the CXL era, the high cost of remote communication is no longer a
barrier when adopting the distributed shared memory model.
Here are
several advantages of CXL:
1.
High-Speed
and Coherent Data Transfer Enabled by CXL:
CXL
connects host processors with remote memory resources, enabling high-speed
load/store instructions with a remote CXL memory access latency of
approximately 300-500 nanoseconds, facilitating high-speed and coherent data
exchange between different nodes.
2.
Memory
Pooling Optimizes Memory Resource Utilization:
Memory
pooling, as a significant advancement, enables the creation of a global memory
resource pool that optimizes overall memory utilization. The CXL switch and
memory controller realize the dynamic allocation and release of memory
resources, thereby minimizing resource inefficiencies and the accompanying
expenses typically found in conventional architectures.
3.
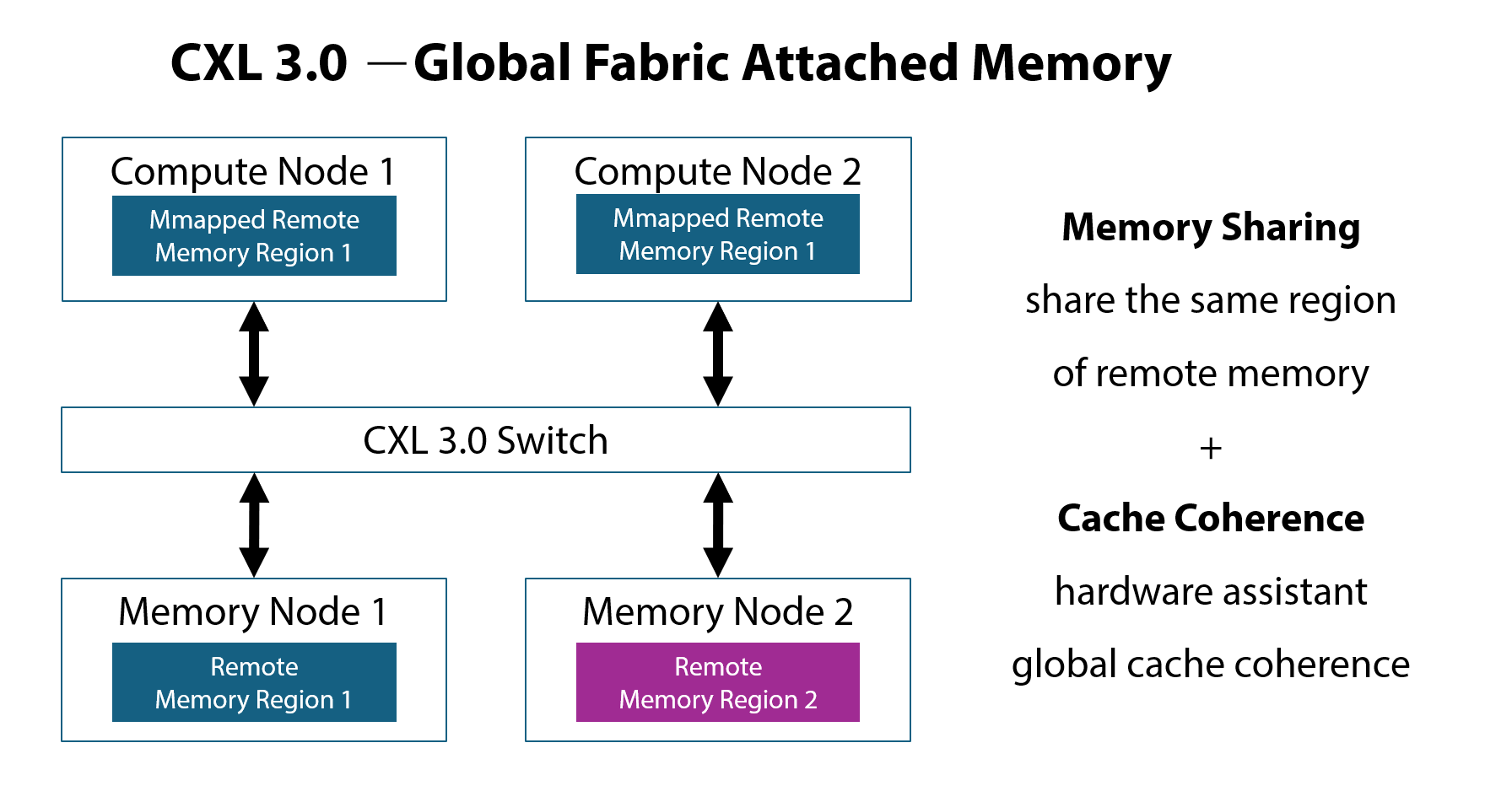
CXL Cache
Coherence Enables Memory Sharing:
CXL
3.0/3.1 ensures memory sharing, enabling the concurrent mapping of identical
memory blocks across multiple machines. Through hardware mechanisms that
maintain cache coherence while multiple machines access memory simultaneously,
a distributed shared memory model is established at the hardware
level.
With the
emergence of CXL, the high cost of remote communication in distributed shared
memory (DSM) is no longer a hindrance. Thus, it's possible to compare
it with the traditional message passing (MP) model to determine which is
more suitable for horizontal scaling computing architectures. However, this
decision depends on specific application requirements and system architectures,
in need of a comprehensive consideration of various factors and making choices
based on actual circumstances. In the current cloud network environment, where
massive data generation makes efficient computing the mainstream
requirement, comparing and analyzing the advantages and disadvantages
of each model is essential.
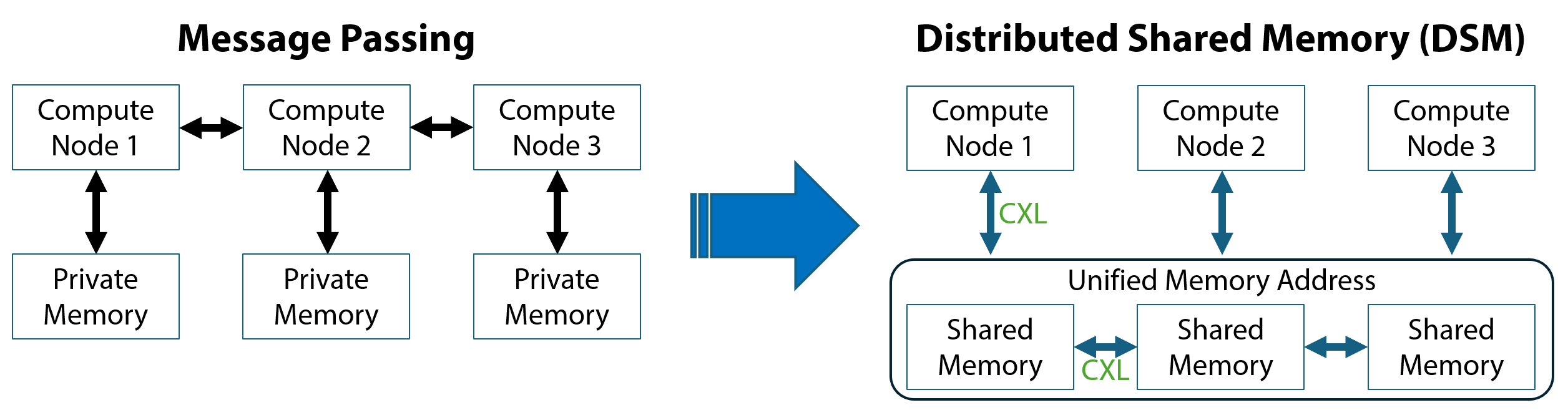
Message
Passing (MP):
1. MP simplifies communication between
distributed nodes through a traditional Send/Receive interface.
2. It assumes a tightly coupled
architecture where each node can only access its local memory.
3. This paradigm is intuitive and
familiar for many programmers, resembling multi-threaded programming on a
single machine.
1. MP typically involves copying data
payloads between nodes, which can incur overhead.
2. It requires explicit data
communication, which can lead to complexities in programming and potential
inefficiencies.
3. MP may not fully leverage
advancements in interconnect technologies like CXL, which prioritize
fine-grained remote load/store operations.
Distributed
Shared Memory (DSM):
1. DSM provides a unified memory
space, abstracting away the complexities of explicit data communication.
2. It facilitates access to remote
memory resources through a pass-by-reference approach, enabling efficient data
sharing.
3. DSM supports a shared-everything
data/state architecture, beneficial for quickly migrating workloads
and load balancing.
1. Managing shared states in DSM
introduces complexities, especially in scenarios involving concurrent access
and partial failures.
2. Traditional DSM approaches may not
be robust against system failures, requiring sophisticated mechanisms
for memory management and resilience.
In the
context of the emerging CXL era, DSM presents renewed potential, especially
with advancements in networking and interconnect
technologies. CXL's support for fine-grained remote memory access aligns
well with the pass-by-reference nature of DSM, offering opportunities for more
flexible and efficient resource utilization. However, transitioning to
CXL-based DSM requires addressing challenges related to managing shared states
and ensuring resilience in the face of partial failures. Despite these challenges,
CXL-based DSM holds promise for applications requiring high flexibility and
scalability, particularly in the evolving landscape of cloud computing.
Reference: https://www.sigops.org/2024/revisiting-distributed-memory-in-the-cxl-era/
