Table of contents
What is CXL Memory Sharing Architecture? A Game-Changer for AI Workloads
In the rapidly evolving landscape of artificial intelligence (AI), the demand for
efficient and scalable computing solutions is higher than ever. Traditional
computing architectures are often challenged by the intensive memory and
processing requirements of modern AI applications. This is where
CXL (Compute Express Link) Memory Sharing Architecture comes into play, providing a
flexible and efficient solution to meet these demands.
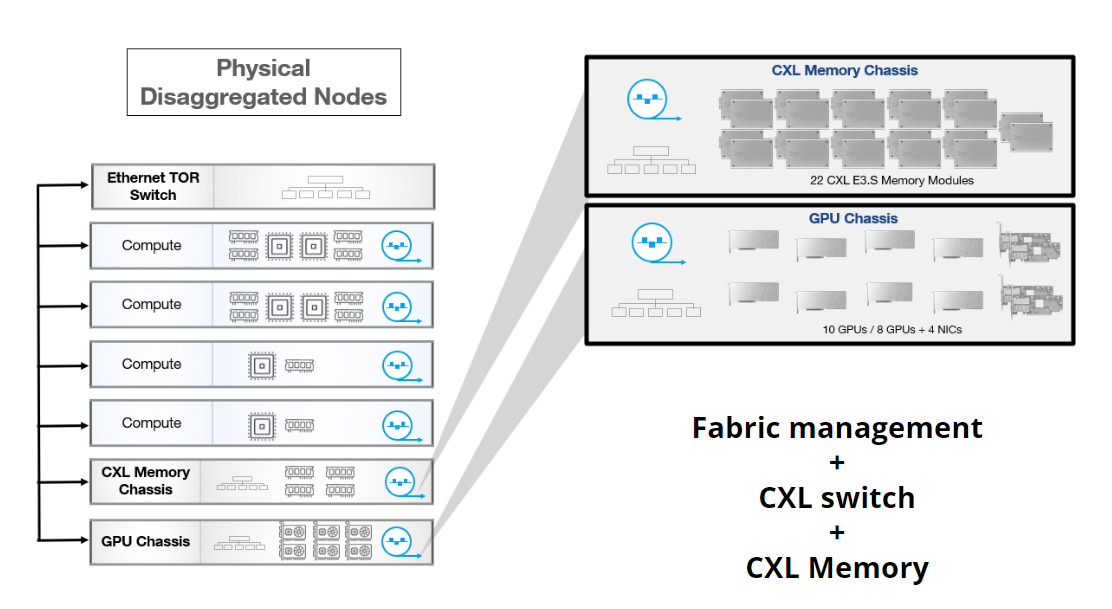
Quick Overview of CXL Memory Sharing
CXL Memory Sharing Architecture allows for the dynamic allocation of resources such
as memory and compute power based on the needs of the applications. This
architecture breaks down the traditional monolithic server structure into
disaggregated nodes, each dedicated to specific resources such as compute,
memory, or GPU. These physical nodes are then logically composed into a unified
system as needed, offering a tailored infrastructure for each workload,
embodying the concept of composable infrastructure.
Real-World Application: AI Cloud
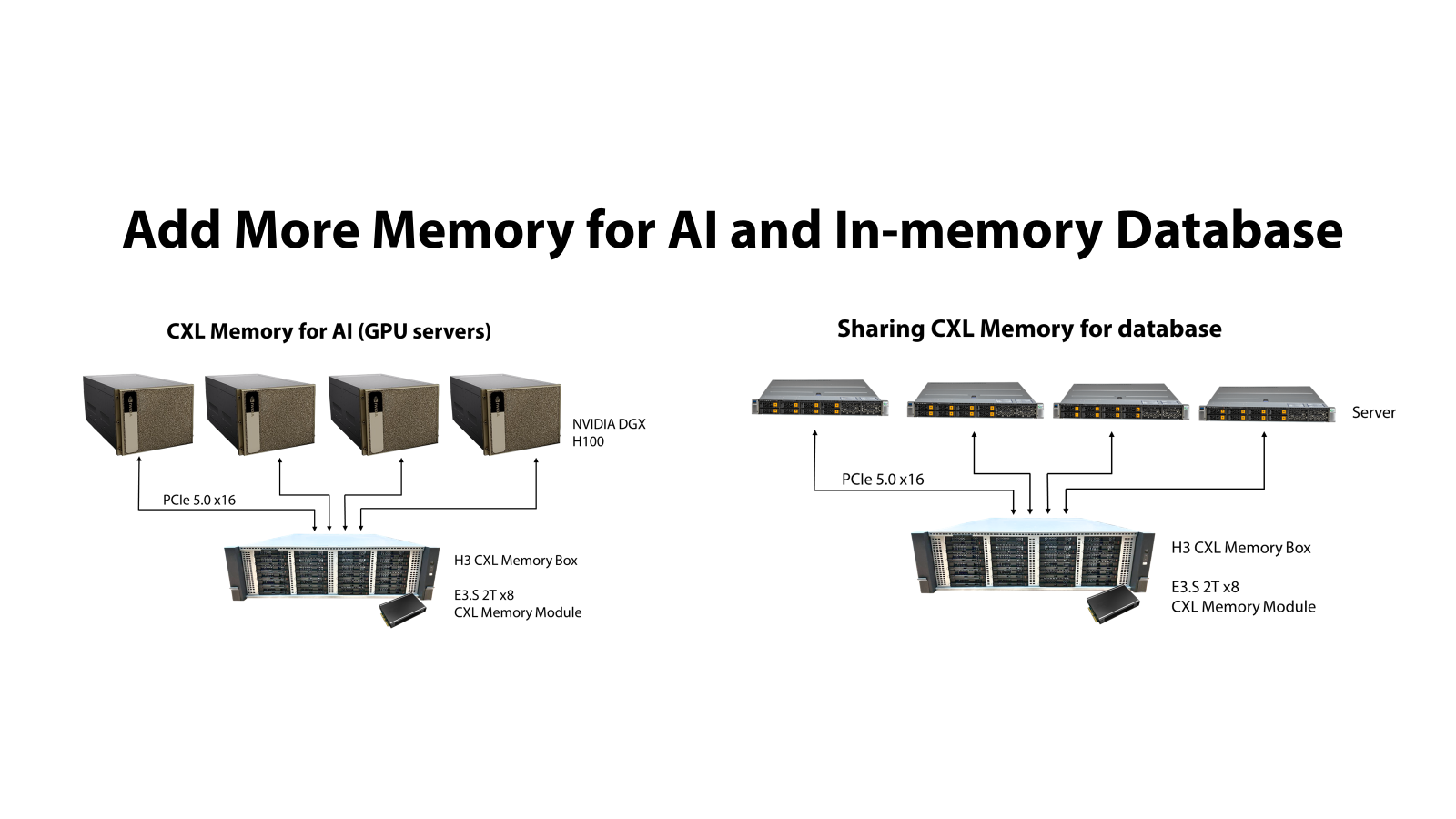
A prime example of CXL Memory Sharing Architecture in action is the AI Cloud,
which utilizes CXL memory for AI GPU servers. This implementation highlights
the potential and benefits of this innovative architecture.
In this setup, the AI GPU servers are connected via PCIe 5.0 x16 to an H3 CXL
Memory Box, which houses E3.S 2T x8 CXL Memory Modules. This configuration
allows the servers to dynamically share memory resources, enhancing both
performance and scalability for AI applications.
Taiwan AI Cloud Usage Case: Key Benefits of CXL Memory Sharing Architecture for AI Workloads
-
Enhanced Performance
CXL memory sharing significantly boosts performance for AI workloads by optimizing memory access and data transfer.
Leveraging Memory Pooling for AI Acceleration
The H3 CXL Memory Box facilitates memory pooling across multiple GPU servers. This allows servers to access a larger, shared memory pool beyond their individual capacities, leading to faster data processing and reduced latency for compute-intensive AI tasks.
High-Bandwidth Connections for Seamless AI Processing
Utilizing PCIe 5.0 x16 connections, the architecture ensures high-bandwidth, low-latency communication between the CXL Memory Box and GPU servers. This robust connectivity is crucial for the demanding data throughput requirements of modern AI workloads.
-
Scalability
-
Flexible Resource Allocation
The architecture supports scaling resources up or down based on the
application’s needs without requiring significant hardware modifications.
-
Future-Proof Infrastructure
As AI models grow in complexity and size, the ability to dynamically allocate
memory and compute resources ensures that the infrastructure can adapt to
future demands.
-
Cost Efficiency
Optimized Resource Utilization: Saving Costs in AI and Cloud Deployments
By sharing memory resources across multiple servers, over-provisioning and
underutilization of memory are minimized, leading to cost savings on both
hardware and energy consumption.
Lower Total Cost of Ownership (TCO) with CXL Memory
The efficient use of resources and the ability to scale as needed contribute to
a lower TCO for organizations implementing this architecture.
-
Simplified Management
Centralized Management for AI Memory Resources
The use of a CXL Memory Box allows for
centralized management of memory resources, simplifying the administration and
optimization of the infrastructure.
Dynamic Reconfiguration for AI Workload Optimization
The infrastructure can be reconfigured
on-the-fly to adapt to different workloads, ensuring optimal performance
without downtime.
Why CXL Memory Sharing Architecture is the Future of AI and High-Performance Computing
The AI Cloud demonstrates the powerful capabilities of CXL Memory Sharing
Architecture, showcasing how it can revolutionize AI and high-performance
computing. By leveraging dynamic resource allocation and high-bandwidth
connections, this architecture not only meets the current demands of AI
workloads but also provides a scalable, cost-effective, and future-proof
solution.
As
AI continues to advance, embracing CXL Memory Sharing Architecture will be
crucial for organizations looking to stay at the forefront of technology,
driving innovation and efficiency in their AI operations.
