Knowledge Base

Nvidia recently released a report on the effectiveness of Big Accelerator Memory (BaM) architecture. BaM leverages GPUDirect RDMA, allowing GPU thread to communicate with SSDs using NVMe queues to ultimately reduce reliance on CPU. According to the paper, the goal of BaM is “to extend GPU memory capacity and enhance the effective storage access bandwidth while providing high-level abstractions for the GPU threads to easily make on-demand, fine-grain access to massive data structures in the extended memory hierarchy.”
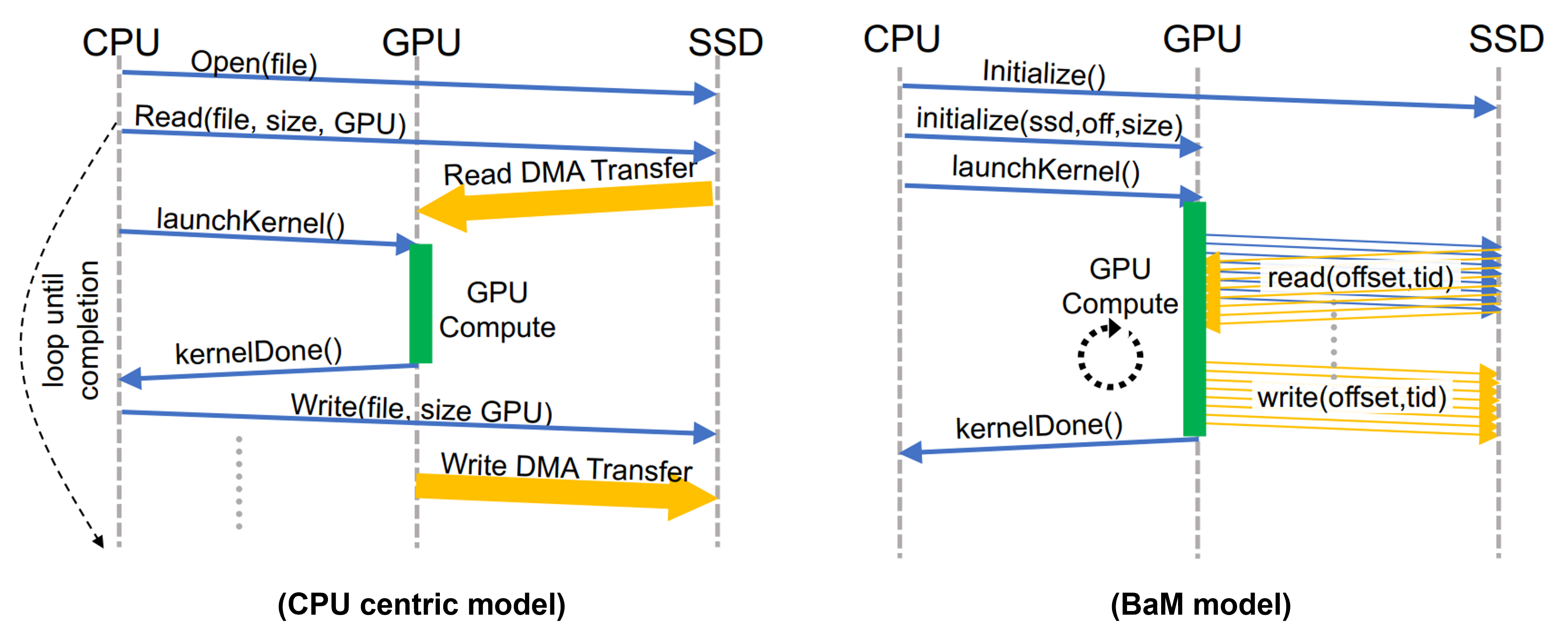
CPU-centric vs GPU-centric computing model. Image from https://arxiv.org/pdf/2203.04910.pdf
In traditional CPU-centric model for GPU computing, CPU manages data transfer and the GPU computes. But it takes much time to load files into host memory before it can be offloaded to GPU. To accommodate massive data, it requires extremely high host-memory bandwidth to overcome this latency. Moreover, IO traffic amplification often occurs during CPU to GPU synchronization, causing inefficient storage bandwidth usage. In CPU-centric architecture, data is transferred from CPU memory to GPU memory in coarse-grain manner, and it results in magnifies IO traffic amplification for data-dependent applications such as graph and data analytics that requires much more fine-grained data access.
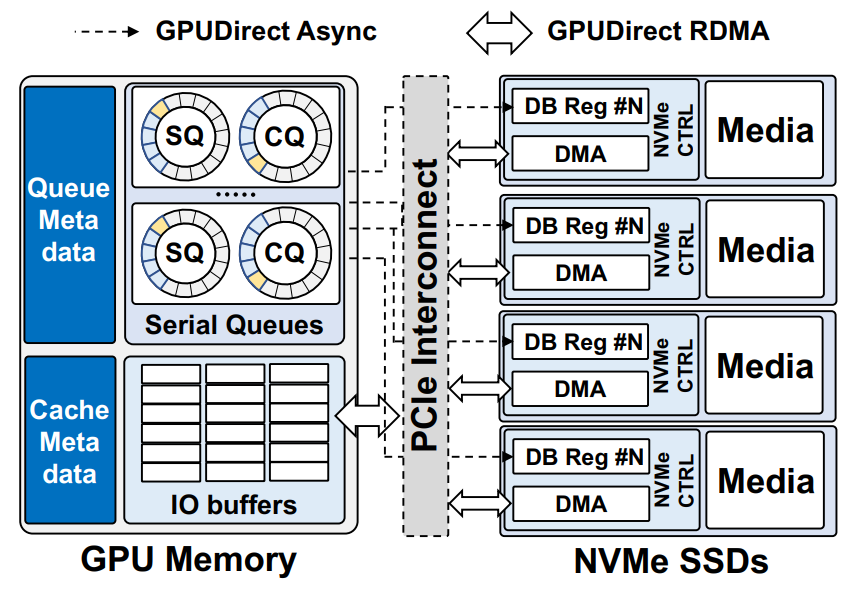
Big Accelerator Memory logical view. Image from https://arxiv.org/pdf/2203.04910.pdf
The BaM architecture solves the aforementioned issue. In addition to extending GPU memory size, this BaM architecture allows GPU threads to do both compute and fetch data from storage, mitigate the costly synchronization between CPU and GPU. The technical details of BaM is quite complicated, you could find them in the paper if you are interested
In terms of hardware setup, BaM requires a GPU to be connected to multiple SSDs at the same time. In order to accommodate this requirement, our Falcon PCIe expansion chassis is a great choice.

Falcon PCIe expansion chassis is a PCIe Gen 4 platform, meaning that the GPU and SSDs can perform peer to peer communicate under the same PCIe switch with PCIe Gen4 x16 bandwidth (32GB/s). The P2P latency between GPU and SSDs under the same PCIe switch is kept under 1 microsecond. Although PCIe may not be the fastest interconnect, it is the most efficient due to its universality. With the PCIe switch, the data can be transferred between the GPU and SSDs without traveling through the host CPU when GPUDirect RDMA is enabled, and it accomplishes the whole idea of the GPU-centric design of BaM.
A Falcon PCIe chassis can accommodate much more devices than a commodity server. Falcon 4016 was used for Nvidia’s BaM experiment, it is able to carry 16 PCIe devices and enables P2P communication at PCIe gen4 performance. For smaller scale BaM system, we also got 8 slot or 4 slot PCIe switch chassis with the same capabilities.
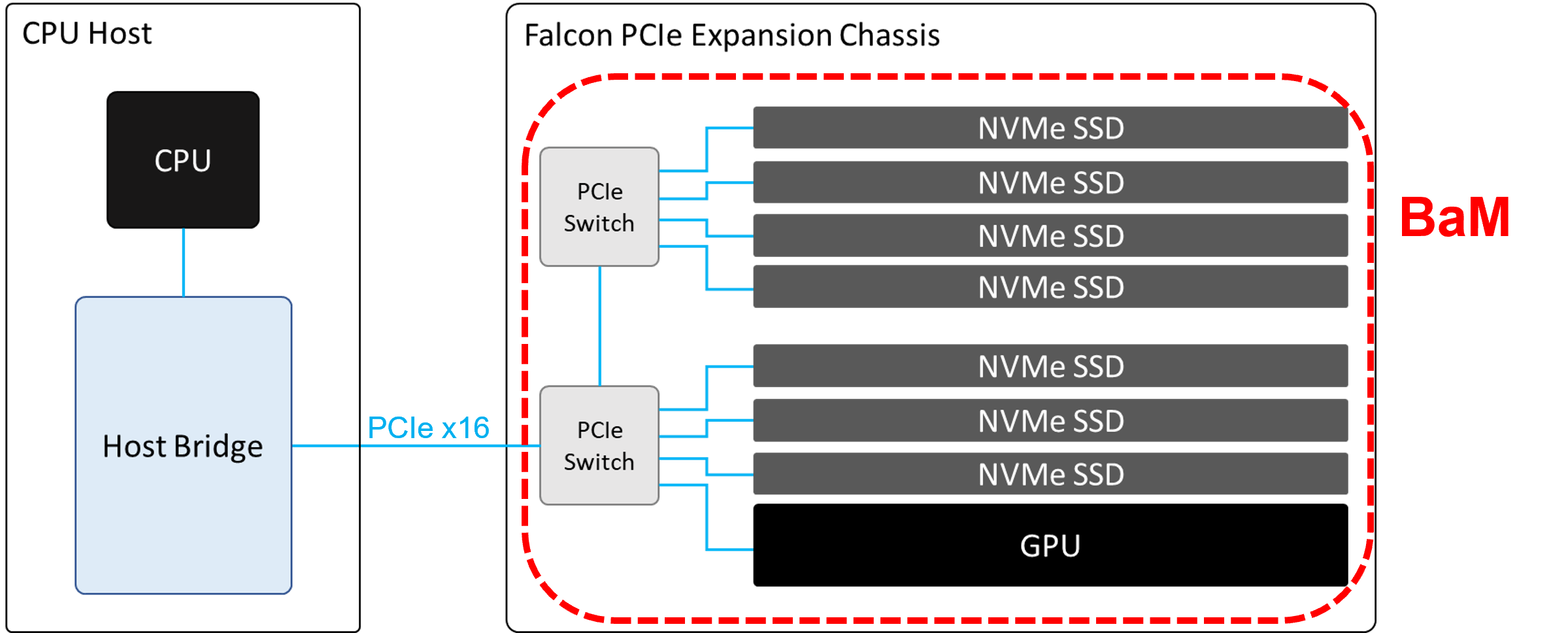
Disaggregated BaM Solution.
One key fact in this BaM architecture is that the GPUs and SSDs are disaggregated from the host CPU. While the purpose of BaM is to minimize the reliance on CPU to orchestrate the accesses to data storage, the requirement of CPU and host memory becomes less significant. With this expansion architecture, GPUs and SSDs can be connected to any commodity server to form a BaM system, meaning that users can easily handle a massive dataset while making efficient use of memory bandwidth for GPU accelerated applications without having to consider the spec of host CPU.